tgoop.com/bigdatai/913
Last Update:
Model2Vec - библиотека для создания компактных и быстрых моделей на основе предобученных Sentence Transformer моделей.
Model2Vec позволяет создавать эмбединг-модели слов и предложений, которые значительно меньше по размеру, но при этом сопоставимы по производительности с исходными Sentence Transformer моделями.
Отличительные особенности:
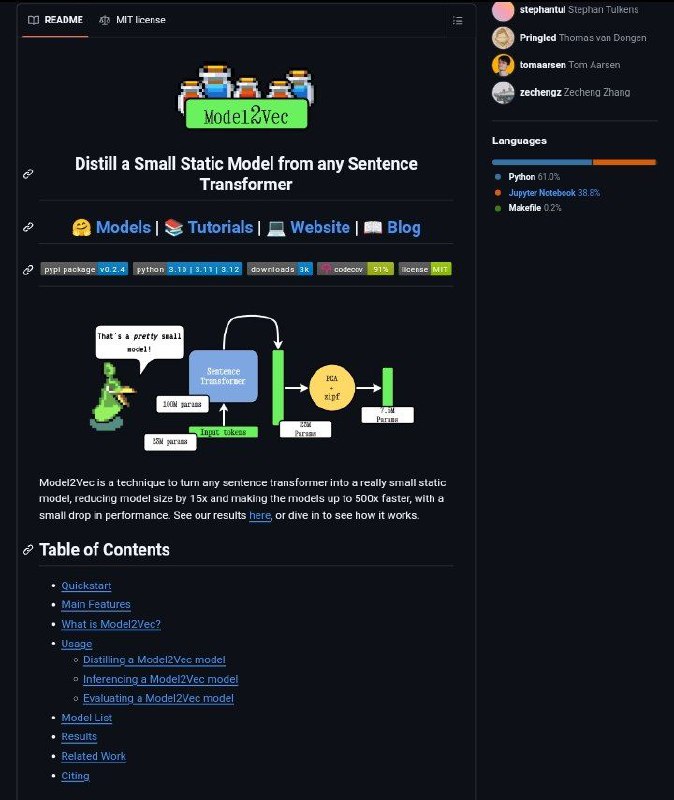
Пайплайн Model2Vec трехэтапный. На первом этапе словарь пропускается через модель Sentence Transformer для получения векторов эмбедингов для каждого слова.
Далее, размерность полученных эмбеддингов сокращается с помощью метода главных компонент (PCA). Наконец, применяется zipf-взвешивание для учета частотности слов в словаре.
Model2Vec работает в двух режимах:
Оценку производительности Model2Vec делали на наборе данных MTEB на задачах PEARL (оценка качества представления фраз) и WordSim (оценка семантической близости слов).
Результаты показывают, что Model2Vec превосходит по производительности GloVe и модели, основанные на WordLlama по всем задачам оценки.
▪️GitHub
@bigdatai