tgoop.com/bigdatai/1213
Last Update:
Совместное исследование Google Research, Принстонского университета, NYU и Еврейского университета в Иерусалиме нашло параллели в обработке естественного языка человеческим мозгом и большими языковыми моделями.
Используя внутричерепные электроды, ученые зафиксировали нейронную активность во время спонтанных диалогов и сравнили ее с внутренними представлениями модели Whisper, разработанной для преобразования речи в текст. Оказалось, что речевые эмбеддинги Whisper коррелируют с активностью в слуховых зонах мозга, а языковые — с областями, ответственными за семантику.
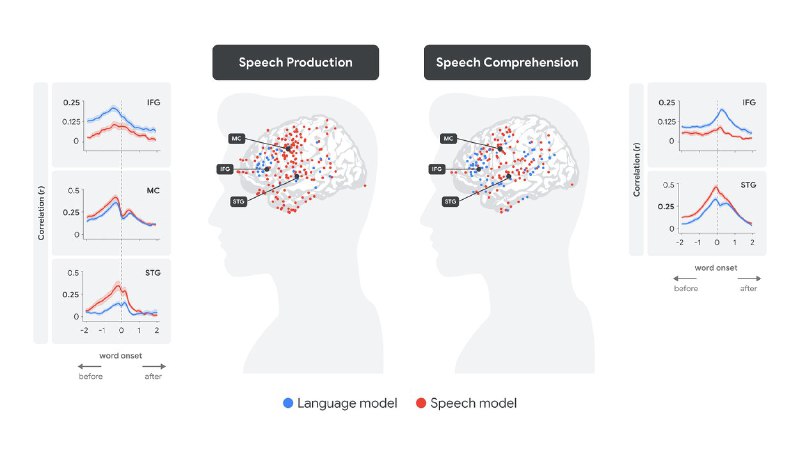
Эксперименты подтвердили догадки: при восприятии речи сначала активируется верхняя височная извилина (STG), обрабатывающая акустические сигналы, а через несколько сотен миллисекунд включается зона Брока (IFG), связанная с декодированием смысла. При воспроизведении речи последовательность обратная: IFG активируется за 500 мс до артикуляции, затем моторная кора планирует движение, а после произнесения слова STG «проверяет» результат. Эти паттерны совпали с динамикой эмбедингов Whisper, хотя модель не обучалась на нейробиологических данных.
Другое интересное совпадение - мозг и LLM используют предсказание следующего слова как ключевую стратегию. Как показали опыты, слушатель бессознательно предугадывает следующие слова, а ошибка предсказания вызывает «нейронное удивление» — механизм, аналогичный обучению с подкреплением в ML. Но архитектурные механизмы у мозга и LLM разные: трансформеры обрабатывают сотни слов параллельно, тогда как мозг анализирует информацию последовательно.
Несмотря на общую «мягкую иерархию» обработки (например, смешение семантических и акустических признаков в IFG и STG), биологические структуры мозга принципиально отличаются от нейронных сетей.
Исследователи подчеркивают: языковые модели (типа ChatGPT) не понимают, как люди общаются в реальной жизни (например, не чувствуют эмоций или культурных особенностей), и не учатся так, как это делает мозг человека с детства. Однако их эмбединги оказались очень полезными для изучения того, как мозг обрабатывает речь.
Ученые надеются, что эти открытия помогут создать нейросети, которые смогут обучаться как люди — медленно, шаг за шагом. А пока Whisper, неожиданно стал «зеркалом» принципов нашего мышления. Кто знает, может, через пару лет ИИ начнёт шутить с нами за чашкой кофе — как друг или коллега по работе.
@ai_machinelearning_big_data
#AI #ML #Research #NLP