tgoop.com/bigdatai/1042
Last Update:
AI-лаборатория Стенфордского университета представила модель MiniVLA — усовершенствованную версию Vision-Language-Action (VLA), компактную альтернативу OpenVLA.
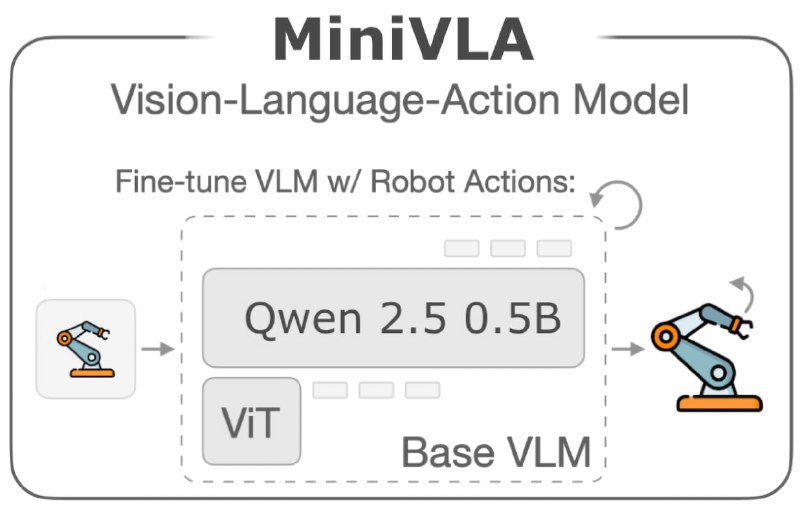
Отличительная особенность MiniVLA - сокращенное в 7 раз количество параметров (1 млрд. против 7 миллиардов у OpenVLA), что дает значительное ускорение процессов обучения и инференса.
В архитектуре MiniVLA используется тот же ViT для обработки изображений, что и в OpenVLA, однако в качестве языковой модели используется Qwen 2.5 0.5B вместо Llama 2 7B.
Обучение языковой модели основано на датасете Llava-1.5-Instruct VQA, аналогично базовой модели Prismatic VLM в OpenVLA. Несмотря на уменьшение размера, MiniVLA демонстрирует сопоставимую с OpenVLA производительность в рамках бенчмарка Libero-90 (61.4% против 62%).
Одно главных усовершенствований MiniVLA - применение векторного квантования (VQ) для кластеризации действий (action chunking). Вместо дискретного представления действий, модель прогнозирует их последовательности, которые кодируются в виде M кодовых индексов с помощью VQ-BeT5. Это существенно повышает производительность на Libero-90.
Так, MiniVLA с VQ h8 (action chunks) достигает 77% успеха, в то время как базовая модель MiniVLA и OpenVLA демонстрируют 61.4% и 62% соответственно.
MiniVLA поддерживает подачу на вход нескольких изображений, что позволяет использовать "историю изображений" и серию снимков с носимых целевым роботом камер. Мульти-кадровая возможность способствует повышению производительности на Libero-90: модель MiniVLA с VQ h8 и историей изображений (history=2) достигает 82% успешности, а с кадрами с новимой камеры — 82.1%.
По сделанным замерам производительности, MiniVLA показывает в 2.5 раза более высокую скорость инференса, чем OpenVLA (12.5Hz против 5Hz) на одном GPU NVIDIA L40s.
@ai_machinelearning_big_data
#AI #ML #VLA #MiniVLA