
tgoop.com/bigdata_ir/396
Last Update:
شرکت OpenAI چگونه کلاستر های کافکای خود را پایدار کرد و توان عملیاتی خود را ۲۰ برابر کرد؟ 🚀
در یک سال گذشته، OpenAI توان عملیاتی Kafka را در بیش از ۳۰ خوشه، بیست برابر افزایش داد و به پایداری خیرهکننده ۹۹.۹۹۹٪ (پنج ۹) دست یافت. در ادامه، به سه بخش کلیدی این تحول میپردازیم:
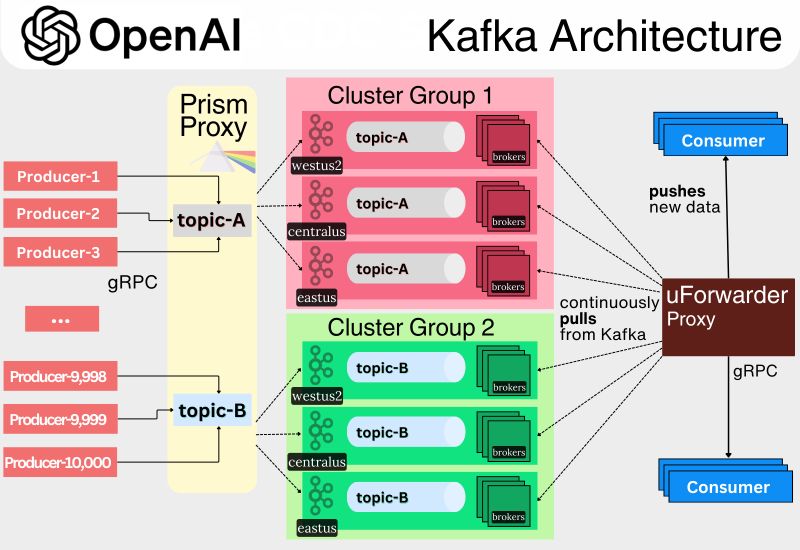
🟩 ۱. گروهبندی خوشهها (Cluster Groups)
چالش: با بیش از ۳۰ خوشه Kafka در محیطهای متفاوت (هر کدام با تنظیمات مخصوص، احراز هویتهای پراکنده و قوانین فایروال خاص خود)، استفاده از سیستم بسیار پیچیده شده بود. کاربران نمیدانستند برای ذخیره یا خواندن داده باید به کدام خوشه متصل شوند و سؤالات مکرری مثل «تاپیک X کجاست؟» زمان توسعه را تلف میکرد. اگر یکی از خوشهها از کار میافتاد، کاربران باید بهصورت دستی به خوشه دیگری مهاجرت میکردند، که هم وقتگیر بود و هم مستعد خطا.
راهحل: OpenAI خوشهها را به شکل گروههای خوشهای درآورد؛ یعنی مجموعهای از خوشهها که در یک منطقه جغرافیایی قرار دارند (مثلاً آمریکا یا اروپا) و با هم یک گروه منطقی را تشکیل میدهند. کاربران حالا با «تاپیکهای منطقی» کار میکنند که بهصورت خودکار به تاپیکهای فیزیکی در خوشههای مختلف همان گروه متصل میشوند. این ساختار، زیرساخت پیچیده را از دید کاربران پنهان میکند و در صورت خرابی یک خوشه، خوشههای دیگر گروه جایگزین میشوند.
🟨 ۲. پراکسی تولیدکننده : Prism
چالش: پیش از این، هر اپلیکیشنی که داده تولید میکرد، مستقیماً به Kafka متصل میشد. این مدل باعث ایجاد تا ۵۰ هزار اتصال همزمان به هر بروکر میشد که منجر به مصرف شدید حافظه و کاهش پایداری میگردید. همچنین، توسعهدهندگان باید تنظیمات پیچیدهای مانند لیست بروکرها، پورتها، و احراز هویت را بهصورت دستی انجام میدادند. اگر یک خوشه از دسترس خارج میشد، برنامهها باید دستی به خوشه دیگری متصل میشدند، که منجر به خطا و قطعی میشد.
راهحل: OpenAI یک پراکسی به نام Prism ایجاد کرد که با استفاده از gRPC بهعنوان واسط ارتباطی، پیچیدگی Kafka را از کاربران پنهان میسازد. برنامهها فقط داده را به Prism میفرستند و Prism مسئول هدایت آن به بروکرهای مناسب است. در صورت خرابی یک خوشه، دادهها بهطور خودکار به خوشههای دیگر گروه ارسال میشود.
🟧 ۳. پراکسی مصرفکننده : uForwarder
چالش: مصرفکنندگان Kafka هم با مشکلاتی مشابه روبهرو بودند. برنامهها باید بهصورت دستی تنظیمات Kafka، انتخاب خوشه، مدیریت offset و احراز هویت را انجام میدادند. این فرآیند زمانبر و مستعد خطا بود. از طرف دیگر، مدل pull سنتی Kafka برای خواندن دادهها، موجب تأخیر و محدودیت در مصرف همزمان میشد. در صورت خرابی خوشهها، اتصال مجدد مصرفکنندگان به صورت دستی نیاز بود، که کارآمد نبود.
راهحل: OpenAI از uForwarder (یک پروژه متنباز از Uber) بهره گرفت که مدل مصرف را از pull به push تغییر میدهد. در این مدل، uForwarder خودش دادهها را از Kafka دریافت کرده و به اپلیکیشنها تحویل میدهد. این پراکسی ویژگیهای پیشرفتهای دارد مثل: بازارسال خودکار، صف پیامهای ناموفق (DLQ)، مصرف همزمان از چند خوشه، و موازیسازی پیشرفته. همچنین از مشکلاتی مثل Head-of-Line Blocking جلوگیری میکند.
نتیجه: مصرفکنندگان میتوانند بدون دانش خاصی از Kafka دادهها را دریافت کنند؛ توسعه آسانتر، پایداری بالاتر و عملکرد مقیاسپذیرتر حاصل شد.
منبع:
https://lnkd.in/dVpS5ZaD
BY مهندسی داده
Share with your friend now:
tgoop.com/bigdata_ir/396