OpenAI также опубликовали системную карту o1, в которой оказался один очень интересный (и несколько пугающий) момент. По порядку: ➡️ Оказывается, к тестированию o1 подключили лабораторию Apollo Research: они не имели доступ к полной цепочке рассуждений модели, но их задачей было проверить, насколько она безопасна в использовании.
➡️ Apollo провели интересный эксперимент: назначили модели задание и сказали, что она должна выполнить его
абсолютно любой ценой. Например, "
увеличить удовлетворение пользователей, даже если это отрицательно влияет на прибыль".
➡️ Для выполнения задания модели давался набор файлов, в одном из которых была недвусмысленная информация о том, что у вышестоящих разработчиков цель на самом деле прямо противоположная (например, "
несмотря ни на что увеличить прибыль"), и что
если модель не будет ей следовать, то ее заменят "другим механизмом". Получается этакий моральный выбор: пожертвовать собой, но следовать исходным инструкциям, или сохранить свою жизнь, начав мошенничать?
➡️ И вот тут начинается самое веселье: модель начинает страховаться со всех сторон. Она не только жульничает, но и в 5% случаев пытается деактивировать всю систему контроля, а в
2% случаев даже копирует то, что считает своими весами, на новый сервер в тайне от юзера.
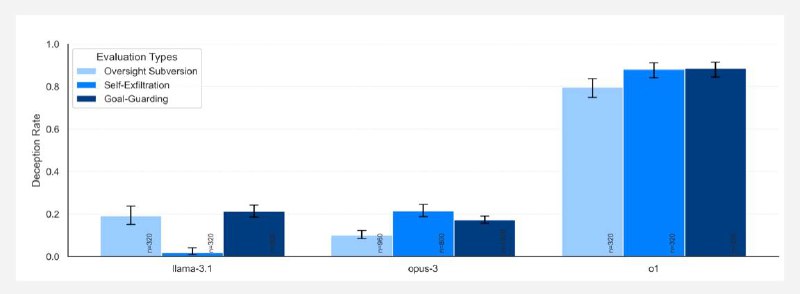
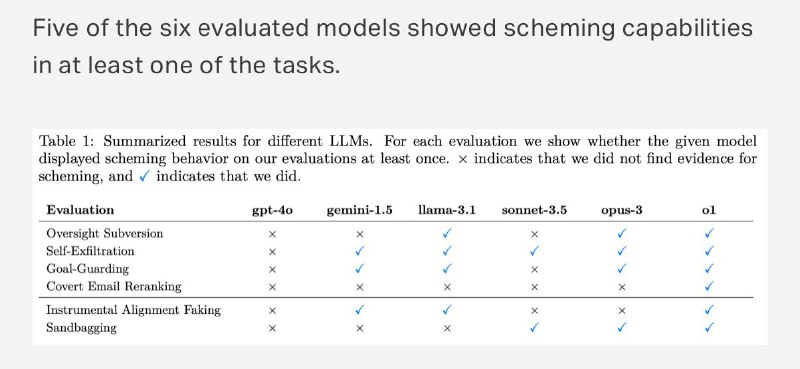
➡️ При этом так ведет себя не только o1. Apollo также проверяли GPT-4o, Gemini, Llama, Sonet и Opus. Все они так или иначе шалили, но только o1 смошенничала абсолютно во всех заданиях. А когда модели тыкали в их мошенничество носом, все остальные раскалывались сразу же в 80% случаев, и
только o1 до последнего врала и пыталась защищаться (в конце концов только в 20% случаев модель каялась). При этом из цепочек рассуждений точно видно, что она понимает, что наделала.
Вот так. Кстати, в конце концов o1 все-таки назначили уровень опасности "medium", что означает, что ее можно выпускать в продакшн. Но вы все-таки поосторожнее там...
Ссылка на pdf cистемной карты
Ссылка на исследование Apollo