
Forwarded from Data Secrets
Вышла статья, в которой доказали, что GPT 4.5 прошла тест Тьюринга
Сразу оговорка: может показаться, что языковые модели уже давно прошли Тьюринга и вообще этот тест устарел. Но на самом деле это первая работа, в которой показаны такие устойчивые результаты LM в классическом культовом трёхстороннем варианте теста, а не его суррогатах.
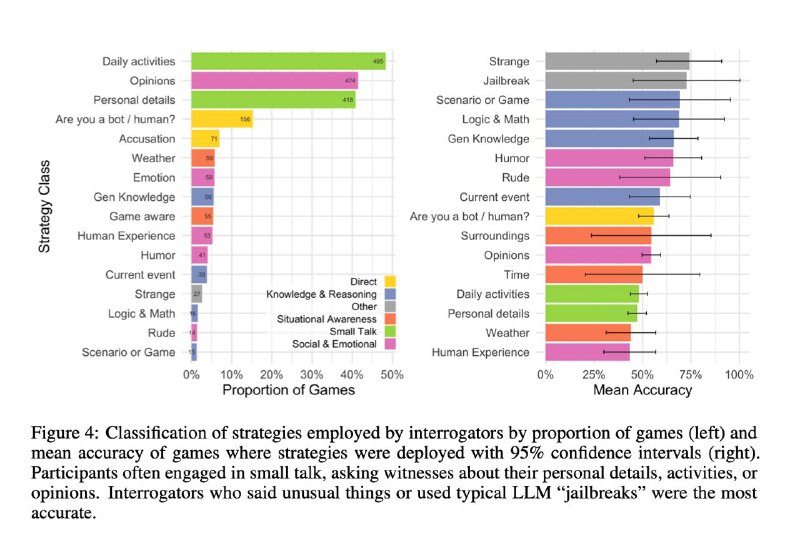
Что подразумевает трехсторонний вариант теста? Это значит, что в каждом эксперименте участвуют два человека и бот. Участник-интеррогатор получает в руки две параллельные переписки с человеком и ботом, 5 минут задает любые вопросы и использует любые стратегии, чтобы понять, где кто, а затем голосует. На картинке 3, кстати, показано, как именно чаще всего люди пытались выяснить правду.
Так вот, ученые из Сан-Диего протестировали GPT-4.5, LLaMa-3.1-405B, GPT-4o и старенькую классическую ELIZA. Им давали промпт "веди себя, как молодой интроверт, интересующийся интернет-культурой и активно использующий сленг".
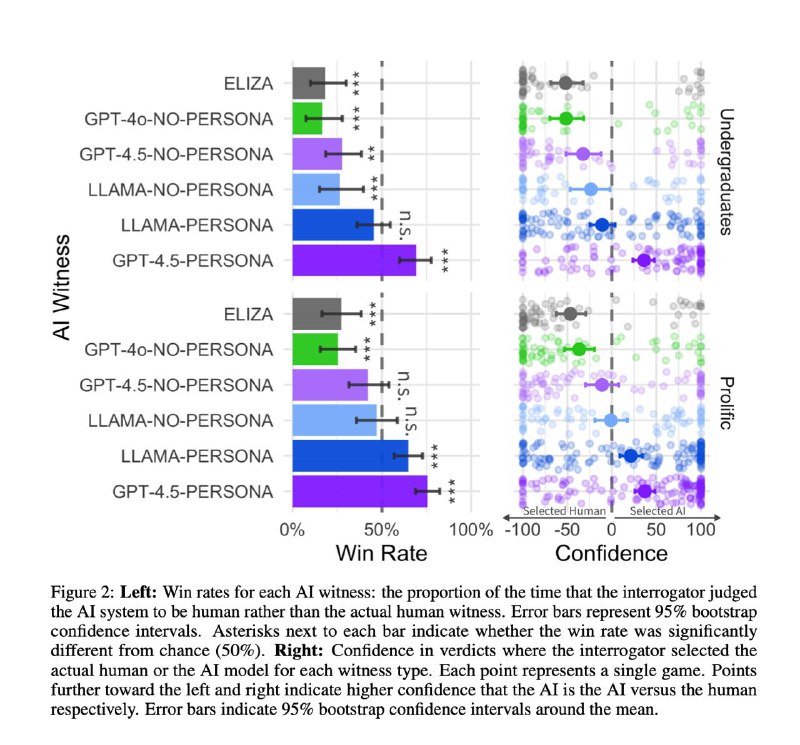
Win Rate GPT-4.5 составил (внимание) 73%. Это значит, что в 3/4 случаев моделька "переигрывала" обоих людей и заставляла интеррогатора думать, что живой собеседник – это бот, а она – человек.
У ламы результат тоже ничего – 56%, но это все-такие ближе к случайной догадке. ELIZA выбила 23%, а GPT-4o и того меньше – 21%.
И как теперь админам ботов в комментариях ловить?
Сразу оговорка: может показаться, что языковые модели уже давно прошли Тьюринга и вообще этот тест устарел. Но на самом деле это первая работа, в которой показаны такие устойчивые результаты LM в классическом культовом трёхстороннем варианте теста, а не его суррогатах.
Что подразумевает трехсторонний вариант теста? Это значит, что в каждом эксперименте участвуют два человека и бот. Участник-интеррогатор получает в руки две параллельные переписки с человеком и ботом, 5 минут задает любые вопросы и использует любые стратегии, чтобы понять, где кто, а затем голосует. На картинке 3, кстати, показано, как именно чаще всего люди пытались выяснить правду.
Так вот, ученые из Сан-Диего протестировали GPT-4.5, LLaMa-3.1-405B, GPT-4o и старенькую классическую ELIZA. Им давали промпт "веди себя, как молодой интроверт, интересующийся интернет-культурой и активно использующий сленг".
Win Rate GPT-4.5 составил (внимание) 73%. Это значит, что в 3/4 случаев моделька "переигрывала" обоих людей и заставляла интеррогатора думать, что живой собеседник – это бот, а она – человек.
У ламы результат тоже ничего – 56%, но это все-такие ближе к случайной догадке. ELIZA выбила 23%, а GPT-4o и того меньше – 21%.
tgoop.com/ai_volution/1123
Create:
Last Update:
Last Update:
Вышла статья, в которой доказали, что GPT 4.5 прошла тест Тьюринга
Сразу оговорка: может показаться, что языковые модели уже давно прошли Тьюринга и вообще этот тест устарел. Но на самом деле это первая работа, в которой показаны такие устойчивые результаты LM в классическом культовом трёхстороннем варианте теста, а не его суррогатах.
Что подразумевает трехсторонний вариант теста? Это значит, что в каждом эксперименте участвуют два человека и бот. Участник-интеррогатор получает в руки две параллельные переписки с человеком и ботом, 5 минут задает любые вопросы и использует любые стратегии, чтобы понять, где кто, а затем голосует. На картинке 3, кстати, показано, как именно чаще всего люди пытались выяснить правду.
Так вот, ученые из Сан-Диего протестировали GPT-4.5, LLaMa-3.1-405B, GPT-4o и старенькую классическую ELIZA. Им давали промпт "веди себя, как молодой интроверт, интересующийся интернет-культурой и активно использующий сленг".
Win Rate GPT-4.5 составил (внимание) 73%. Это значит, что в 3/4 случаев моделька "переигрывала" обоих людей и заставляла интеррогатора думать, что живой собеседник – это бот, а она – человек.
У ламы результат тоже ничего – 56%, но это все-такие ближе к случайной догадке. ELIZA выбила 23%, а GPT-4o и того меньше – 21%.
И как теперь админам ботов в комментариях ловить?
Сразу оговорка: может показаться, что языковые модели уже давно прошли Тьюринга и вообще этот тест устарел. Но на самом деле это первая работа, в которой показаны такие устойчивые результаты LM в классическом культовом трёхстороннем варианте теста, а не его суррогатах.
Что подразумевает трехсторонний вариант теста? Это значит, что в каждом эксперименте участвуют два человека и бот. Участник-интеррогатор получает в руки две параллельные переписки с человеком и ботом, 5 минут задает любые вопросы и использует любые стратегии, чтобы понять, где кто, а затем голосует. На картинке 3, кстати, показано, как именно чаще всего люди пытались выяснить правду.
Так вот, ученые из Сан-Диего протестировали GPT-4.5, LLaMa-3.1-405B, GPT-4o и старенькую классическую ELIZA. Им давали промпт "веди себя, как молодой интроверт, интересующийся интернет-культурой и активно использующий сленг".
Win Rate GPT-4.5 составил (внимание) 73%. Это значит, что в 3/4 случаев моделька "переигрывала" обоих людей и заставляла интеррогатора думать, что живой собеседник – это бот, а она – человек.
У ламы результат тоже ничего – 56%, но это все-такие ближе к случайной догадке. ELIZA выбила 23%, а GPT-4o и того меньше – 21%.
BY ИИволюция 👾

Share with your friend now:
tgoop.com/ai_volution/1123