
tgoop.com/ai_volution/1047
Last Update:
OpenAI представила новое поколение аудио-моделей: точнее Whisper 3 и с эмоциями!
Теперь любой разработчик может использовать мощнейшие голосовые модели прямо в API:
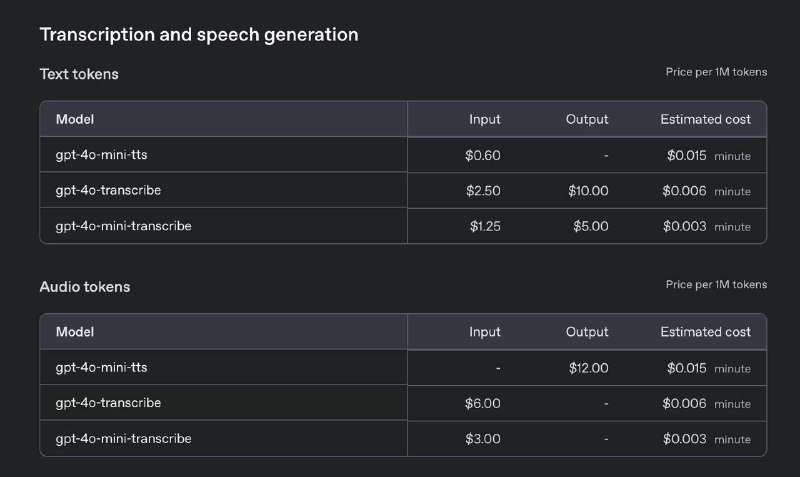
Speech-to-Text (доступна в API):
- Новые модели GPT-4o-transcribe и GPT-4o-mini-transcribe значительно превзошли по точности Whisper v3 и другие популярные решения.
- Они показывают лучший результат (более низкий WER) даже при сложных условиях: шумном фоне, акцентах или быстрой речи.
- Идеально подходят для колл-центров, расшифровок встреч и подкастов.
Text-to-Speech (доступна в API):
- Новая модель GPT-4o-mini-tts умеет не просто озвучивать текст, но и выражать эмоции и интонации по вашей инструкции.
- Например, можно попросить модель говорить «как сочувствующий оператор поддержки», профессиональный диктор или даже рассказчик историй.
- Голосовой AI становится максимально естественным и персонализированным.
- Whisper 3 был хорош, но OpenAI подняла планку ещё выше: новые модели дают точность и гибкость, которых раньше не было.
Официальная новость: https://openai.com/index/introducing-our-next-generation-audio-models/
Послушать разные варианты озвучки можно на этой площадке: www.openai.fm
Пора пробовать в проектах!
ИИволюция
BY ИИволюция 👾
Share with your friend now:
tgoop.com/ai_volution/1047