
tgoop.com/ai_newz/3114
Last Update:
Scaling Laws with Vocabulary: Larger Models Deserve Larger Vocabularies
В последнее время, увеличение размера словаря токенизатора для LLM всплывало в основном как метод улучшения многоязычного перформанса. Но часто народ забывает, что увеличение размера словаря ещё и позволяет пропустить через LLM больше текста при том же компьюте (потому что в каждый токен, в среднем, будет влезать больше букв), тем самым повысив эффективность тренировки и улучшив результаты модели. Но где предел такому росту эффективности?
В этом пейпере авторы натренировали ряд моделей с разными размерами словаря токенизатора и вывели формулу для расчёта оптимальных размеров. Вот основные выводы:
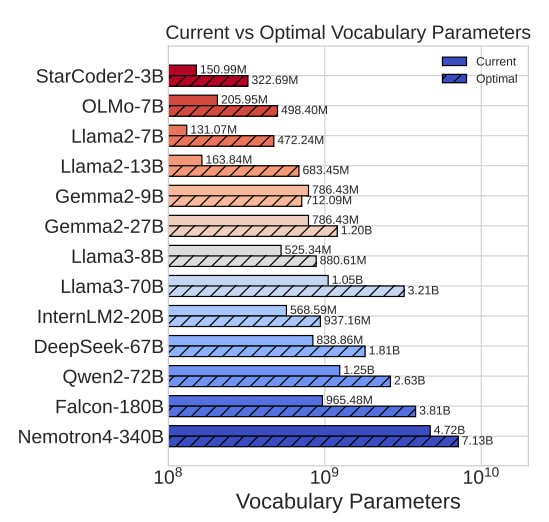
➖ У большинства современных моделей словари слишком маленькие, результаты можно заметно улучшить просто его увеличив.
➖ Оптимальный размер словаря растёт очень медленно - с увеличением модели в 100 раз, оптимальный словарь растёт в 10.
➖ Модели учатся хуже как со словарём больше оптимального, так и меньше оптимального.
➖ Если есть ограничение в размере датасета, иногда лучше использовать неоптимальный токенизатор, чтобы увеличить количество токенов, и тем самым улучшить результаты.
➖ Оптимальный размер словаря токенизатора Llama 3.1 405B - полмиллиона токенов, в 4 раза больше оригинального словаря.
Токенизаторы — это всё ещё очень плохо изученная тема, и даже большие лабы делают тут банальные ошибки. Если хотите разобраться как они работают сейчас, то вот лучший туториал.
Пейпер
@ai_newz
BY эйай ньюз
Share with your friend now:
tgoop.com/ai_newz/3114