
tgoop.com/abstractDL/281
Last Update:
Your Transformer is Secretly Linear
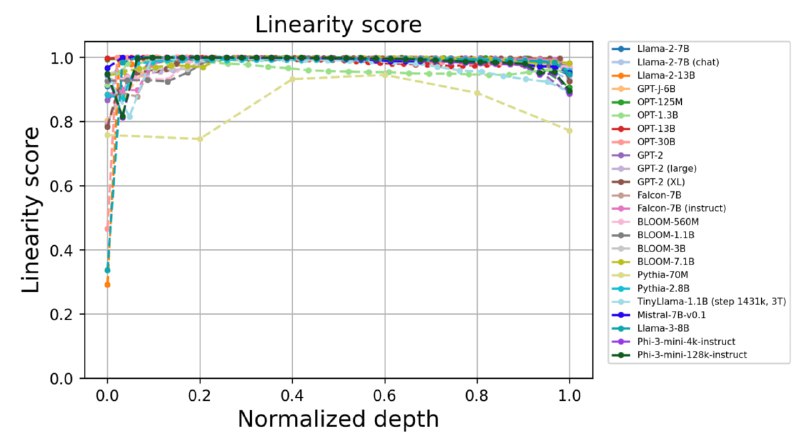
Мою новую статью приняли на ACL 🎉. Мы обнаружили, что большинство слоёв языковых моделей линейны на 99%! Это значит, что из любого слоя LLM можно выкинуть этэншн, нормализацию и даже feed-forward с активацией, оставив лишь один nn.Linear(), а модель будет работать, будто бы ничего не поменялось!
Такая неадекватная линейность наблюдается во всех трансформерах-декодерах (GPT, Llama, Mistral, и тд.). Мы предполагаем, что это связано с feature triggering режимом, то есть нелинейность "вспыхивает" на очень небольшом количестве важных токенов (что-то похожее было в статье Deja Vu). Поэтому совсем уж много слоёв таким образом заменить нельзя, нелинейность хоть сама по себе и крошечная, но её влияние очень быстро накапливается.
Ещё из интересных наблюдений — по мере претрейна нелинейность растёт, а во время файнтюнинга (или RLHF) она всегда падает. Исходя из этого, мы придумали регуляризацию, которая немножко усиливает нелинейность и бустит метрики на претрейне.
P.S. Вместе с кодом для оценки линейности слоёв трансформеров мы выкладываем и код к прошлой нашей статье про анизотропию и внутреннюю размерность.
Статья, GitHub, хабр
BY AbstractDL
Share with your friend now:
tgoop.com/abstractDL/281