
tgoop.com/Machine_learn/3412
Last Update:
FireRedASR: Open-Source Industrial-Grade Mandarin Speech Recognition Models from Encoder-Decoder to LLM Integration
24 Jan 2025 · Kai-Tuo Xu, Feng-Long Xie, Xu Tang, Yao Hu ·
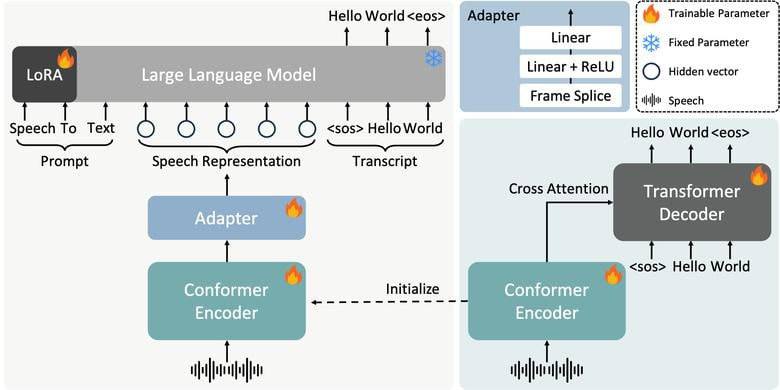
We present FireRedASR, a family of large-scale automatic speech recognition (ASR) models for Mandarin, designed to meet diverse requirements in superior performance and optimal efficiency across various applications. FireRedASR comprises two variants: FireRedASR-LLM: Designed to achieve state-of-the-art (SOTA) performance and to enable seamless end-to-end speech interaction. It adopts an Encoder-Adapter-LLM framework leveraging large language model (LLM) capabilities. On public Mandarin benchmarks, FireRedASR-LLM (8.3B parameters) achieves an average Character Error Rate (CER) of 3.05%, surpassing the latest SOTA of 3.33% with an 8.4% relative CER reduction (CERR). It demonstrates superior generalization capability over industrial-grade baselines, achieving 24%-40% CERR in multi-source Mandarin ASR scenarios such as video, live, and intelligent assistant. FireRedASR-AED: Designed to balance high performance and computational efficiency and to serve as an effective speech representation module in LLM-based speech models. It utilizes an Attention-based Encoder-Decoder (AED) architecture. On public Mandarin benchmarks, FireRedASR-AED (1.1B parameters) achieves an average CER of 3.18%, slightly worse than FireRedASR-LLM but still outperforming the latest SOTA model with over 12B parameters. It offers a more compact size, making it suitable for resource-constrained applications. Moreover, both models exhibit competitive results on Chinese dialects and English speech benchmarks and excel in singing lyrics recognition.
Paper: https://arxiv.org/pdf/2501.14350v1.pdf
Code: https://github.com/fireredteam/fireredasr
Datasets: LibriSpeech - AISHELL-1 - AISHELL-2 - WenetSpeech
https://www.tgoop.com/deep_learning_proj
BY Machine learning books and papers
Share with your friend now:
tgoop.com/Machine_learn/3412