tgoop.com/Data_fusion/232
Last Update:
В лаборатории AIRI придумали способ легко масштабировать трансформеры на контекст 2 миллиона токенов
Вчера на конференции Data Fusion прошла церемония награждения Data Fusion Awards (запись). Премию за научный прорыв выиграл Айдар Булатов: он стал одним из авторов работы, в которой предложили способ расширения контекстного окна трансформеров при линейном росте вычислительных затрат.
Нас работа очень заинтересовала, и позже мы познакомились с Айдаром на постерной сессии лично, чтобы немного расспросить его о статье. Главная идея: соединить трансформеры и рекуррентный механизм памяти.
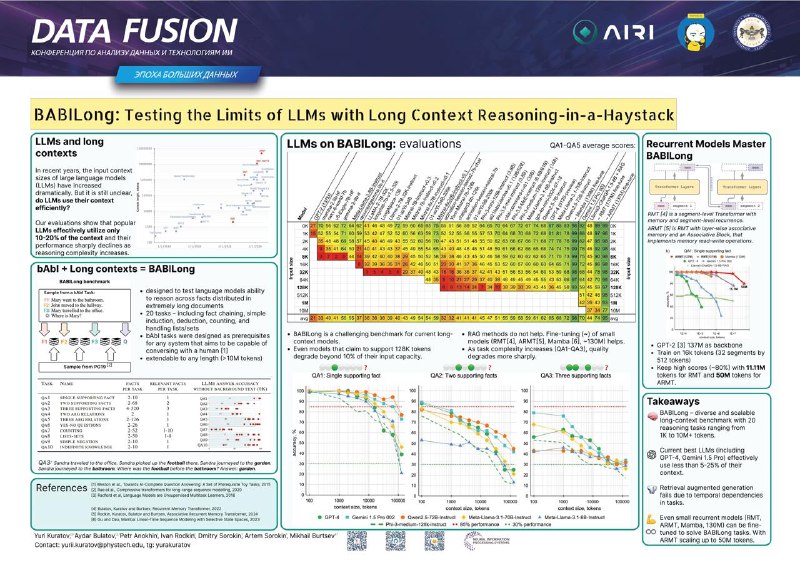
Мы разделяем текст на кусочки и обрабатываем их последовательно. При этом в начало каждого сегмента добавляются векторы памяти, которая обновляется на каждой следующей итерации. Таким образом, self‑attention считается только внутри сегмента, но при этом мы все равно с каждым разом храним все больше и больше информации о тексте.
Масштабируется это действительно хорошо: ребята обучали модель только на последовательностях длины до 3.5к токенов, но на тестах она спокойно выдерживает контекст до 2 миллионов (а позже и до 50 миллионов на модификациях)! Вот гитхаб и статья.
Кстати, на основе этой работы Айдар в команде с Юрием Куратовым и другими авторами также создали бенчмарк BABILong для оценки моделей на длинном контексте. Сейчас на этом бенчмарке тестируют свои модели многие ведущие лабы: Google, Meta, OpenAI. Мы, кстати, даже несколько раз о нем писали, но то, что он был сделан в AIRI, узнали только вчера. Эта работа тоже была в числе победителей премии.
Поздравляем