
tgoop.com/AlgorithmDesign_DataStructuer/1759
Last Update:
🧠 تا حالا شده بخوای یه مدل زبانی بزرگ مثل LLaMA بتونه تصویر رو بفهمه، بدون اینکه بخوای آموزشش بدی؟
توی یه مقاله جدید یه روش خیلی جالب پیشنهاد شده به اسم:
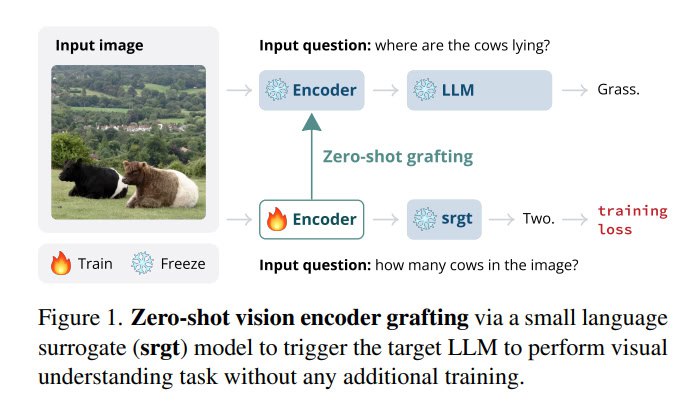
Zero-Shot Vision Encoder Grafting
ایدهش اینه:
میان یه مدل کوچیک درست میکنن (بهش میگن surrogate) که از لایههای ابتدایی همون LLM استفاده میکنه. بعد یه رمزگذار بینایی (Vision Encoder) رو روی این مدل کوچیک آموزش میدن.
📌 حالا رمزگذار بینایی رو میگیرن و مستقیم میچسبونن به LLM اصلی! بدون اینکه LLM نیاز به آموزش داشته باشه
نکته: نماد (❄️)Freeze نشان میده که وزن های این رمزگذار در طول این فرایند به روز نمی شوند در واقع از قبل آموزش دیده و ثابت است.
نماد Traing (🔥) نشان دهنده که این مدل خاص در حال آموزش است.
https://arxiv.org/abs/2505.22664
Link github : https://github.com/facebookresearch/zero
#هوش_مصنوعی
📣👨💻 @AlgorithmDesign_DataStructuer
BY Algorithm design & data structure
Share with your friend now:
tgoop.com/AlgorithmDesign_DataStructuer/1759