
tgoop.com/AlgorithmDesign_DataStructuer/1757
Last Update:
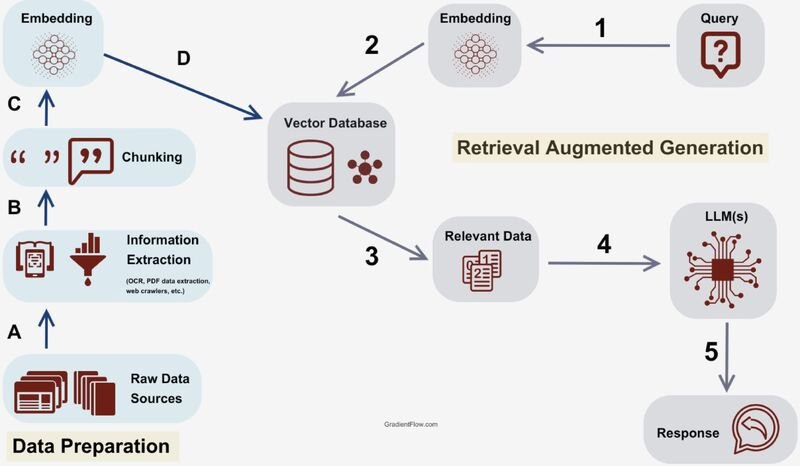
میدونید معماری RAG (تولید افزودهشده با بازیابی) چطوری کار میکنه؟
🔶 مرحله A: آمادهسازی دادهها
همهچیز از منابع دادهی خام شروع میشه؛ مثل فایلهای PDF، صفحات وب، یا اسناد مختلف.
🔶 مرحله B: استخراج اطلاعات
دادهها با کمک ابزارهایی مثل OCR یا خزندههای وب استخراج میشن.
🔶 مرحله C: تقسیمبندی (Chunking)
برای اینکه اطلاعات بهتر فهمیده بشن، به تکههای کوچکتر (چانکها) تقسیم میشن.
🔶 مرحله D: تبدیل به بردار (Embedding)
اینجا هر تکه اطلاعات به شکلی تبدیل میشه که مدل زبانی بتونه بفهمه: یعنی بردار!
🔶 مرحله 2: ذخیرهسازی در پایگاه برداری (Vector Database)
بردارها در یک دیتابیس مخصوص ذخیره میشن تا بعداً قابل جستجو باشن.
🔍 مرحله 1: کاربر سوال میپرسه (Query)
کاربر سوالی میفرسته؛ اونم به بردار تبدیل میشه!
🔄 مرحله 3: جستجو در پایگاه برداری
سیستم دادههای مرتبط با سوال رو پیدا میکنه.
🤖 مرحله 4: ارسال به مدل زبانی (LLM)
دادههای بازیابیشده به مدل زبان بزرگ (مثل GPT) داده میشه تا پاسخ تولید بشه.
✅ مرحله 5: تولید پاسخ نهایی
در نهایت، پاسخ کامل و دقیق برمیگرده.
#هوش_مصنوعی
📣👨💻 @AlgorithmDesign_DataStructuer
BY Algorithm design & data structure
Share with your friend now:
tgoop.com/AlgorithmDesign_DataStructuer/1757