
tgoop.com/AlgorithmDesign_DataStructuer/1728
Last Update:
🔹 درک سادهی MapReduce با یک تصویر! 🔹
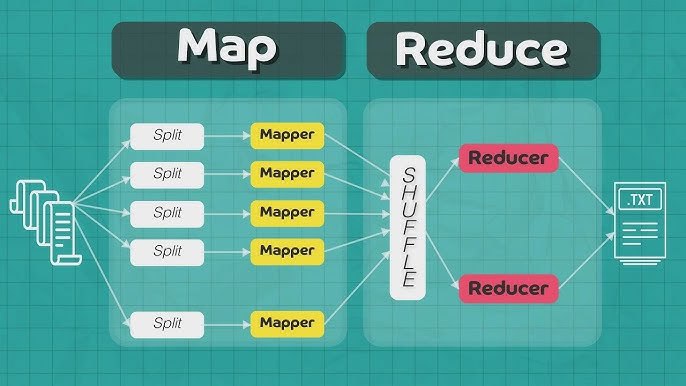
📊 اگر با دادههای بزرگ (Big Data) سروکار داری، حتماً اسم MapReduce به گوشت خورده! این تصویر مراحل اجرای این مدل محبوب پردازش داده رو خیلی ساده و شفاف نشون میده 👇
🟢 مرحله Map (نگاشت):
دادههای خام (مثلاً چند فایل بزرگ متنی) به چند بخش کوچکتر تقسیم میشن (Split)،
هر بخش توسط یک Mapper پردازش میشه تا به صورت جفتهای کلید-مقدار (Key-Value Pairs) تبدیل بشه.
⚙️ مرحله Shuffle (مرتبسازی و گروهبندی):
نتایج Mapperها بر اساس کلیدها گروهبندی و مرتب میشن تا آماده بشن برای مرحله بعد.
🔴 مرحله Reduce (کاهش):
هر Reducer دادههای گروهبندیشده رو دریافت و جمعبندی یا تجزیهوتحلیل میکنه.
در نهایت، خروجی نهایی (مثلاً یک فایل متنی نهایی) تولید میشه. 📄
✅ مزیت اصلی MapReduce اینه که میتونه دادههای خیلی بزرگ رو روی چندین سرور بهصورت موازی پردازش کنه.
📌در واقع MapReduce یکی از پایههای مهم در سیستمهای مثل Hadoop برای تحلیل دادههای عظیمه!
#هوش_مصنوعی
📣👨💻 @AlgorithmDesign_DataStructuer
BY Algorithm design & data structure
Share with your friend now:
tgoop.com/AlgorithmDesign_DataStructuer/1728