
RL с ллмами притянули к рекомендашкам. Тюнили Qwen 2.5 3B.
Оптимизировались на двух задачах:
Задача поиска товаров (Product Search). Пользователь пишет запрос, LLM запрос переписывает или уточняет, после чего система на основе переработанного запроса (например, через BM25) возвращает список кандидатов.
Задача последовательных рекомендаций (Sequential Recommendation). Здесь нужно предсказать следующий товар на основе истории взаимодействий пользователя (типа предыдущие покупки или что он просматривал). LLM генерирует текстовое описание, которое который пользователь скорее всего купит следующим (тут могут быть ключевые характеристики товара, тип продукта и тд).
ревард для RLя получали по метрикам от рекомендательных систем - NDCG@K, Recall@K (например тут можно подробнее про них узнать)
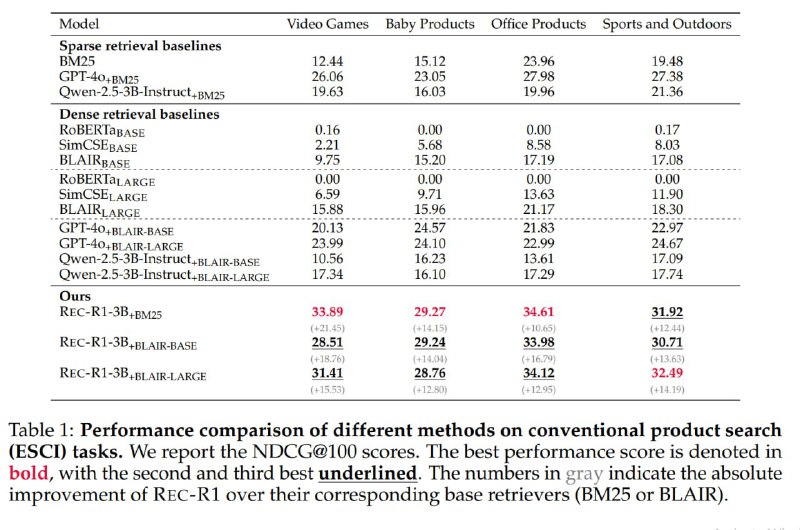
С RLем сильно улучшили метрички, 1 и 2 скрин.
Сравнили RL и с SFT тюнингом (данные генерили с GPT 4o конкретно под рекомендашки) и потом померили на обычных бенчах производительность.
Результы на 3 скрине. Кое-где после SFT просели результаты, с RLем вроде поровнее получилось.
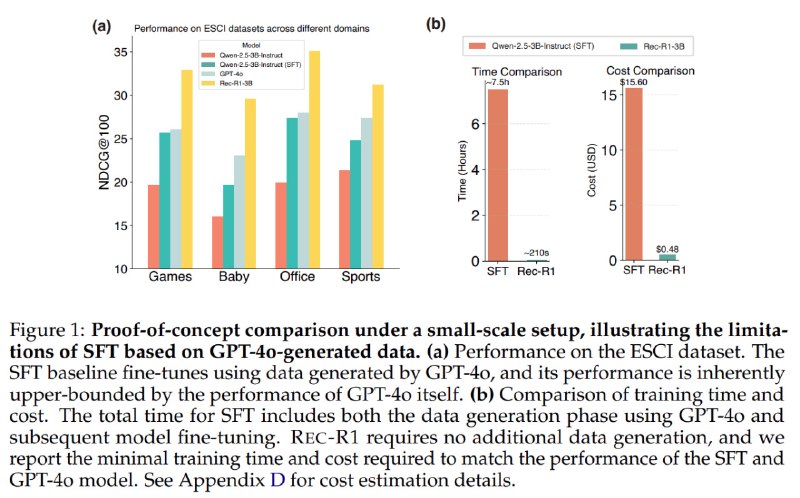
Ну и у RLя результаты вроде получше получились чем у SFT на небольших тестах (4 скрин по порядку, a). И SFT на сгенерированных GPT 4о данных не превосходит просто GPT 4o на задаче. (авторы даже теоремку доказывают, что политика обученная на SFT не может быть лучше политики которой сгенерили данные. т.е. не будет в данном случае лучше 4o)
На скрине 4 b сравнивают цену и время на RL для того чтобы получить ту же производительность что у генерации данных на SFT + трен.
Ну как-то быстро конечно.
Подробнее читаем тут
Rec-R1: Bridging Generative Large Language Models and User-Centric Recommendation Systems via Reinforcement Learning
https://arxiv.org/abs/2503.24289
Код тута:
https://github.com/linjc16/Rec-R1
PS все крутые статьи собираем и делаем проектики в https://www.tgoop.com/researchim
Оптимизировались на двух задачах:
Задача поиска товаров (Product Search). Пользователь пишет запрос, LLM запрос переписывает или уточняет, после чего система на основе переработанного запроса (например, через BM25) возвращает список кандидатов.
Задача последовательных рекомендаций (Sequential Recommendation). Здесь нужно предсказать следующий товар на основе истории взаимодействий пользователя (типа предыдущие покупки или что он просматривал). LLM генерирует текстовое описание, которое который пользователь скорее всего купит следующим (тут могут быть ключевые характеристики товара, тип продукта и тд).
ревард для RLя получали по метрикам от рекомендательных систем - NDCG@K, Recall@K (например тут можно подробнее про них узнать)
С RLем сильно улучшили метрички, 1 и 2 скрин.
Сравнили RL и с SFT тюнингом (данные генерили с GPT 4o конкретно под рекомендашки) и потом померили на обычных бенчах производительность.
Результы на 3 скрине. Кое-где после SFT просели результаты, с RLем вроде поровнее получилось.
Ну и у RLя результаты вроде получше получились чем у SFT на небольших тестах (4 скрин по порядку, a). И SFT на сгенерированных GPT 4о данных не превосходит просто GPT 4o на задаче. (авторы даже теоремку доказывают, что политика обученная на SFT не может быть лучше политики которой сгенерили данные. т.е. не будет в данном случае лучше 4o)
На скрине 4 b сравнивают цену и время на RL для того чтобы получить ту же производительность что у генерации данных на SFT + трен.
Ну как-то быстро конечно.
Подробнее читаем тут
Rec-R1: Bridging Generative Large Language Models and User-Centric Recommendation Systems via Reinforcement Learning
https://arxiv.org/abs/2503.24289
Код тута:
https://github.com/linjc16/Rec-R1
PS все крутые статьи собираем и делаем проектики в https://www.tgoop.com/researchim
👍12🔥4❤2😱1
tgoop.com/AGI_and_RL/1010
Create:
Last Update:
Last Update:
RL с ллмами притянули к рекомендашкам. Тюнили Qwen 2.5 3B.
Оптимизировались на двух задачах:
Задача поиска товаров (Product Search). Пользователь пишет запрос, LLM запрос переписывает или уточняет, после чего система на основе переработанного запроса (например, через BM25) возвращает список кандидатов.
Задача последовательных рекомендаций (Sequential Recommendation). Здесь нужно предсказать следующий товар на основе истории взаимодействий пользователя (типа предыдущие покупки или что он просматривал). LLM генерирует текстовое описание, которое который пользователь скорее всего купит следующим (тут могут быть ключевые характеристики товара, тип продукта и тд).
ревард для RLя получали по метрикам от рекомендательных систем - NDCG@K, Recall@K (например тут можно подробнее про них узнать)
С RLем сильно улучшили метрички, 1 и 2 скрин.
Сравнили RL и с SFT тюнингом (данные генерили с GPT 4o конкретно под рекомендашки) и потом померили на обычных бенчах производительность.
Результы на 3 скрине. Кое-где после SFT просели результаты, с RLем вроде поровнее получилось.
Ну и у RLя результаты вроде получше получились чем у SFT на небольших тестах (4 скрин по порядку, a). И SFT на сгенерированных GPT 4о данных не превосходит просто GPT 4o на задаче. (авторы даже теоремку доказывают, что политика обученная на SFT не может быть лучше политики которой сгенерили данные. т.е. не будет в данном случае лучше 4o)
На скрине 4 b сравнивают цену и время на RL для того чтобы получить ту же производительность что у генерации данных на SFT + трен.
Ну как-то быстро конечно.
Подробнее читаем тут
Rec-R1: Bridging Generative Large Language Models and User-Centric Recommendation Systems via Reinforcement Learning
https://arxiv.org/abs/2503.24289
Код тута:
https://github.com/linjc16/Rec-R1
PS все крутые статьи собираем и делаем проектики в https://www.tgoop.com/researchim
Оптимизировались на двух задачах:
Задача поиска товаров (Product Search). Пользователь пишет запрос, LLM запрос переписывает или уточняет, после чего система на основе переработанного запроса (например, через BM25) возвращает список кандидатов.
Задача последовательных рекомендаций (Sequential Recommendation). Здесь нужно предсказать следующий товар на основе истории взаимодействий пользователя (типа предыдущие покупки или что он просматривал). LLM генерирует текстовое описание, которое который пользователь скорее всего купит следующим (тут могут быть ключевые характеристики товара, тип продукта и тд).
ревард для RLя получали по метрикам от рекомендательных систем - NDCG@K, Recall@K (например тут можно подробнее про них узнать)
С RLем сильно улучшили метрички, 1 и 2 скрин.
Сравнили RL и с SFT тюнингом (данные генерили с GPT 4o конкретно под рекомендашки) и потом померили на обычных бенчах производительность.
Результы на 3 скрине. Кое-где после SFT просели результаты, с RLем вроде поровнее получилось.
Ну и у RLя результаты вроде получше получились чем у SFT на небольших тестах (4 скрин по порядку, a). И SFT на сгенерированных GPT 4о данных не превосходит просто GPT 4o на задаче. (авторы даже теоремку доказывают, что политика обученная на SFT не может быть лучше политики которой сгенерили данные. т.е. не будет в данном случае лучше 4o)
На скрине 4 b сравнивают цену и время на RL для того чтобы получить ту же производительность что у генерации данных на SFT + трен.
Ну как-то быстро конечно.
Подробнее читаем тут
Rec-R1: Bridging Generative Large Language Models and User-Centric Recommendation Systems via Reinforcement Learning
https://arxiv.org/abs/2503.24289
Код тута:
https://github.com/linjc16/Rec-R1
PS все крутые статьи собираем и делаем проектики в https://www.tgoop.com/researchim
BY Агенты ИИ | AGI_and_RL


Share with your friend now:
tgoop.com/AGI_and_RL/1010