
🖋 Решение задач со дня стажёра Яндекса, часть 2
Давайте наберём 160 огоньков 🔥, и мы сделаем третью часть решения задач с этого поста
P.S. Спасибо за внимательность телезрителю из Москвы))
Давайте наберём 160 огоньков 🔥, и мы сделаем третью часть решения задач с этого поста
P.S. Спасибо за внимательность телезрителю из Москвы))
🔥159❤5
🏆 Тренировки по ML и Yandex Cup!
Этой осенью Яндекс запускает 2 классных движа, в которых стоит поучаствовать:
1. Тренировки по Machine Learning
Помимо классических тренировок по алгоритмам, в этом году запускается новое направление тренировок по ML, созданное совместно с ШАДом.
Начало 30-го октября, успевайте зарегистрироваться!
2. Yandex Cup
В этом чемпионате стоит поучаствовать как продвинутым data scientist’ам, так и новичкам, чтобы прокачать свои навыки (а возможно и выиграть приз). Всего есть 6 направлений, в которые входят Аналитика и Машинное обучение. Соревнование делится на 3 этапа:
1) 23-29 октября - Квалификация
2) 4 ноября - Полуфинал
3) 2-3 декабря - Финал
Примеры задач на аналитику: *тык*
Аннотации к ML задачам: *тык*
Регистрация открыта до 23:00 29 октября по МСК!
Ставьте:
❤️ – если записались на тренировки
🔥– если зарегались на Yandex Cup
❤️🔥 – если зарегистрировались и туда, и туда
Этой осенью Яндекс запускает 2 классных движа, в которых стоит поучаствовать:
1. Тренировки по Machine Learning
Помимо классических тренировок по алгоритмам, в этом году запускается новое направление тренировок по ML, созданное совместно с ШАДом.
Начало 30-го октября, успевайте зарегистрироваться!
2. Yandex Cup
В этом чемпионате стоит поучаствовать как продвинутым data scientist’ам, так и новичкам, чтобы прокачать свои навыки (а возможно и выиграть приз). Всего есть 6 направлений, в которые входят Аналитика и Машинное обучение. Соревнование делится на 3 этапа:
1) 23-29 октября - Квалификация
2) 4 ноября - Полуфинал
3) 2-3 декабря - Финал
Примеры задач на аналитику: *тык*
Аннотации к ML задачам: *тык*
Регистрация открыта до 23:00 29 октября по МСК!
Ставьте:
❤️ – если записались на тренировки
🔥– если зарегались на Yandex Cup
❤️🔥 – если зарегистрировались и туда, и туда
Yandex Cup — чемпионат по программированию
Машинное обучение — Yandex Cup
Попробуйте свои силы в решении нестандартных задач
❤26❤🔥14👍6🔥3
Про ML-секции в Яндексе
Нашлось старое, но вполне ещё актуальное видео про то, как проходить ML-секции в Я.
На примере кейса (система подсказка географических объектов) разбирается то, какие вопросы задавать и на что обращать внимание.
Короткий план решения:
1. Стоит уточнить постановку задачи и узнать, где решение будет использовать реализованы ли уже какие-то элементы решения
2. Метрики: бизнес-метрики и технические метрики
3. Что делать на старте? Нужно ли здесь вообще машинное обучение?
4. Если всё-таки хотим обучать модель: данные для обучения, разбиение на train-test, какую модель стоит обучать, как её принимать
Видео тут
Если хотите больше историй про прохождение собеседований - накидайте 🔥 этому посту!)
Нашлось старое, но вполне ещё актуальное видео про то, как проходить ML-секции в Я.
На примере кейса (система подсказка географических объектов) разбирается то, какие вопросы задавать и на что обращать внимание.
Короткий план решения:
2. Метрики: бизнес-метрики и технические метрики
3. Что делать на старте? Нужно ли здесь вообще машинное обучение?
4. Если всё-таки хотим обучать модель: данные для обучения, разбиение на train-test, какую модель стоит обучать, как её принимать
Видео тут
Если хотите больше историй про прохождение собеседований - накидайте 🔥 этому посту!)
YouTube
Как проходить секции по машинному обучению: помощь разработчикам, собеседующимся в Яндекс
Подробнее о наших секциях по машинному обучению читайте в статье на хабре: https://habr.com/ru/company/yandex/blog/475584/
🔥57❤8👍6❤🔥1
🎨 Классный ресурс, чтобы освежить в памяти темы по ML
Если вы более-менее знаете английский и хотите быстро повторить темы по Machine Learning - вам сюда
Всего тут три больших блока, в каждом из которых есть много интересных визуализаций:
– ML
– ML-Engineering
– Проективная геометрия
– Еще немного по DL
Ставьте огоньки 🔥, если штука и вправду полезная, и сердечки ❤️, если добавили пост себе в избранное))
Если вы более-менее знаете английский и хотите быстро повторить темы по Machine Learning - вам сюда
Всего тут три больших блока, в каждом из которых есть много интересных визуализаций:
– ML
– ML-Engineering
– Проективная геометрия
– Еще немного по DL
Ставьте огоньки 🔥, если штука и вправду полезная, и сердечки ❤️, если добавили пост себе в избранное))
{kind=link}
🔥43❤23👍1
🎲 50 задачек по теории вероятностей с решениями
В дополнение к посту с подборкой задачников по теории вероятностей делимся с вами оригиналом книжки с 50-ю задачами на тервер и их решениями! Если вы не боитесь английского, то хорошей идеей перед собеседованием будет сесть и прорешать десяток таких задачек, чтобы освежить свои знания по теорверу 🙂. А если боитесь - то в посте с подборкой есть перевод задачника
Вот одна из задачек оттуда:
Купоны в коробках с хлопьями пронумерованы от 1 до 5, и для получения приза требуется набор из 5 различных купонов (1, 2, 3, 4 и 5). Если в каждой коробке по одному купону, то сколько коробок в среднем потребуется для того, чтобы получить такой набор?
Ответ:
≈ 11.42. А решение можно найти на 29-й страничке сборника
Кстати, некоторые задачки из сборника встречаются в бесплатном курсе по теории вероятности от Computer Science Club, который оочень рекомендуется к прохождению
Зажигайте огоньки 🔥 под этим постом и делитесь в комментариях своими любимыми задачками по теории вероятностей)
В дополнение к посту с подборкой задачников по теории вероятностей делимся с вами оригиналом книжки с 50-ю задачами на тервер и их решениями! Если вы не боитесь английского, то хорошей идеей перед собеседованием будет сесть и прорешать десяток таких задачек, чтобы освежить свои знания по теорверу 🙂. А если боитесь - то в посте с подборкой есть перевод задачника
Вот одна из задачек оттуда:
Купоны в коробках с хлопьями пронумерованы от 1 до 5, и для получения приза требуется набор из 5 различных купонов (1, 2, 3, 4 и 5). Если в каждой коробке по одному купону, то сколько коробок в среднем потребуется для того, чтобы получить такой набор?
Ответ:
Кстати, некоторые задачки из сборника встречаются в бесплатном курсе по теории вероятности от Computer Science Club, который оочень рекомендуется к прохождению
Зажигайте огоньки 🔥 под этим постом и делитесь в комментариях своими любимыми задачками по теории вероятностей)
Яндекс Диск
fifty-challenging-problems-in-probability-with-solutions.pdf
Посмотреть и скачать с Яндекс Диска
🔥65❤6👍1
Воскресили ссылку в закрепленном сообщении 🙂
В ближайшее время докинем туда в том числе и последние посты!
Ребята, очень хочется как-то оживить наш канал, что-то в последнее время больно мало активности здесь. Это можно сделать как внутренне (проводя прямые эфиры-мероприятия), так и внешне (устраивая розыгрыши с другими каналами)
В связи с этим, решили провести пару опросов:
В ближайшее время докинем туда в том числе и последние посты!
Ребята, очень хочется как-то оживить наш канал, что-то в последнее время больно мало активности здесь. Это можно сделать как внутренне (проводя прямые эфиры-мероприятия), так и внешне (устраивая розыгрыши с другими каналами)
В связи с этим, решили провести пару опросов:
❤23👍9❤🔥5
⏳ Несколько хороших статей про метрику Retention
Наверное, одна из важнейших метрик у любого продукта - Retention. Если вы еще не знаете, что это такое - бегом читайте статьи ниже! А если думаете, что знаете, - читайте тем более, ведь всего за полчаса можно получить столько интересных мыслей 🙂
– Как считать Retention rate: про разницу между N-day retention и Rolling Retention + еще несколько способов расчета метрики
– Рычаги влияния на Retention: на примере Uber'a показывают, какие ключевые факторы определяют Retention и как можно повлиять на них
– Долгосрочный Retention Matter: на примере мобильных игр разбирают, почему нужно учитывать долгосрочный Retention и как именно это можно делать
Мы заметили, что посты про метрики собирают маловато реакций(
Давайте исправим это – если вам заходят такие посты, жмите огонёк 🔥 под ними!
Наверное, одна из важнейших метрик у любого продукта - Retention. Если вы еще не знаете, что это такое - бегом читайте статьи ниже! А если думаете, что знаете, - читайте тем более, ведь всего за полчаса можно получить столько интересных мыслей 🙂
– Как считать Retention rate: про разницу между N-day retention и Rolling Retention + еще несколько способов расчета метрики
– Рычаги влияния на Retention: на примере Uber'a показывают, какие ключевые факторы определяют Retention и как можно повлиять на них
– Долгосрочный Retention Matter: на примере мобильных игр разбирают, почему нужно учитывать долгосрочный Retention и как именно это можно делать
Мы заметили, что посты про метрики собирают маловато реакций(
Давайте исправим это – если вам заходят такие посты, жмите огонёк 🔥 под ними!
GoPractice
ᐈ Как считать Retention rate, N-day Retention и Rolling Retention - GoPractice
✓ Какие способы расчета Retention существуют? В чем особенность Rolling Retention? В чем разница между Retention на основе 24-часовых окон и на основе календарных дней?
🔥87👍11❤1
🎻 Ансамбли машинного обучения за 30 минут
Недавно лазили по блогу Александра Дьяконова и наткнулись на статью 2019 года про ансамбли, которая и по сей день остаётся одним из самых подробных обзоров про ансамблирование в рунете.
В посте рассматриваются:
– Комитеты (голосование) / усреднение
– Бэггинг
– Случайные леса
– Бустинг
– Стекинг и блендинг
– Однородные ансамбли
– Ансамбли старой школы
Чтобы полностью понять публикацию, достаточно базовых знаний ML и теории вероятностей.
Читайте статью, и не забывайте ставить огоньки под нашими постами! 🔥
Недавно лазили по блогу Александра Дьяконова и наткнулись на статью 2019 года про ансамбли, которая и по сей день остаётся одним из самых подробных обзоров про ансамблирование в рунете.
Ансамблем (Ensemble, Multiple Classifier System) называется алгоритм, который состоит из нескольких алгоритмов машинного обучения
В посте рассматриваются:
– Комитеты (голосование) / усреднение
– Бэггинг
– Случайные леса
– Бустинг
– Стекинг и блендинг
– Однородные ансамбли
– Ансамбли старой школы
Чтобы полностью понять публикацию, достаточно базовых знаний ML и теории вероятностей.
Читайте статью, и не забывайте ставить огоньки под нашими постами! 🔥
Анализ малых данных
Ансамбли в машинном обучении
В этом блоге было уже много постов про разные частные случаи ансамблей. Теперь просто их общая систематизация (точнее, вступительная часть в повествовании про ансамблирование), в результате которой…
🔥48😁1🤩1
🔬 3 популярных метода кластеризации
Кластеризация - это задача разбиения объектов на конечное число классов без обучающей выборки, то есть задача обучения без учителя
Самые популярные методы кластеризации это:
1. K-Means
2. Иерархическая агломеративная кластеризация
3. DBSCAN
Разобраться в них вам поможет:
1. Хендбук от Яндекса (понятно, что нужно быть более-менее математически подкованным)
2. Видяшки от StatQuest c наглядным объяснением:
–[ENG] K-Means
–[ENG] Hierarchical Clustering
–[ENG] DBSCAN
3. Документация scikit-learn на русском
4.[ENG] Ноутбук с демонстрацией применения этих методов в решении реальной задачи
5. Интерактивные визуализации, чтобы посмотреть, как работают методы:
[ENG] K-Means
[ENG] DBSCAN
Ставьте лайки 👍 на этот пост, и пишите в комментариях, про что вы бы ещё хотели увидеть публикации
P.S. Конечно, это не все методы. На картинке можно увидеть результаты работы этих и других методов кластеризации на различных датасетах 🙂
Кластеризация - это задача разбиения объектов на конечное число классов без обучающей выборки, то есть задача обучения без учителя
Самые популярные методы кластеризации это:
1. K-Means
2. Иерархическая агломеративная кластеризация
3. DBSCAN
Разобраться в них вам поможет:
1. Хендбук от Яндекса (понятно, что нужно быть более-менее математически подкованным)
2. Видяшки от StatQuest c наглядным объяснением:
–[ENG] K-Means
–[ENG] Hierarchical Clustering
–[ENG] DBSCAN
3. Документация scikit-learn на русском
4.[ENG] Ноутбук с демонстрацией применения этих методов в решении реальной задачи
5. Интерактивные визуализации, чтобы посмотреть, как работают методы:
[ENG] K-Means
[ENG] DBSCAN
Ставьте лайки 👍 на этот пост, и пишите в комментариях, про что вы бы ещё хотели увидеть публикации
P.S. Конечно, это не все методы. На картинке можно увидеть результаты работы этих и других методов кластеризации на различных датасетах 🙂
{kind=link}
👍56🔥6❤5
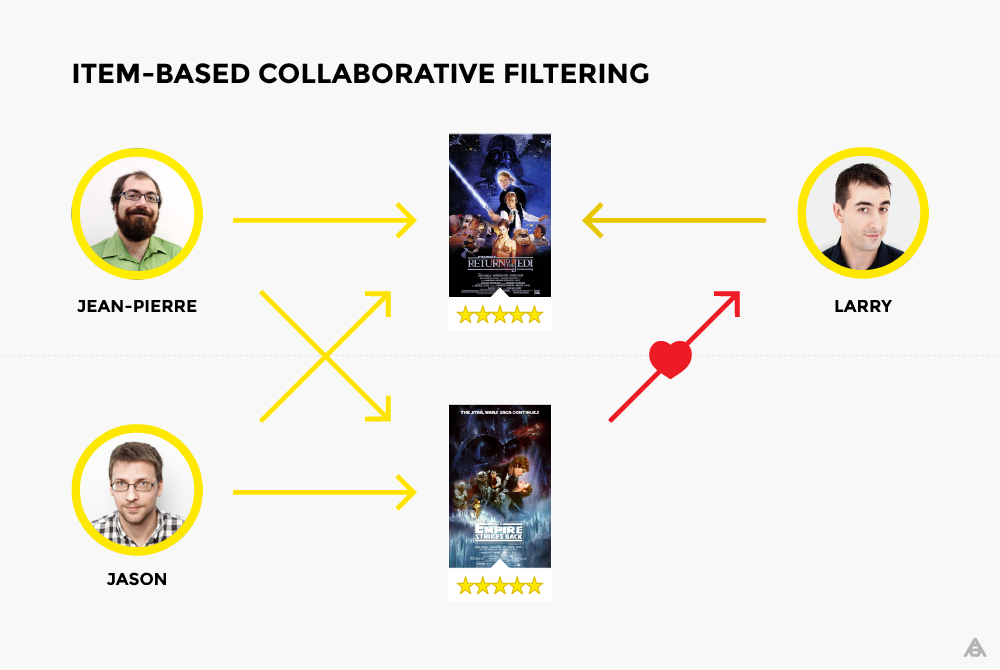
🎞 Порекомендуйте, пожалуйста, фильм на вечер
Один из самых простых способ порекомендовать что-то - коллаборативная фильтрация 🙂
Есть два подхода к коллаборативной фильтрации:
1. User-based – ищутся похожие пользователи
2. Item-based – ищутся похожие продукты
Глобально алгоритм такой:
1. Найти, насколько другие пользователи (продукты) в базе данных похожи на данного пользователя (продукт).
2. По оценкам других пользователей (продуктов) предсказать, какую оценку даст данный пользователь данному продукту, учитывая с большим весом тех пользователей (продукты), которые больше похожи на данный.
Эта статья хоть и старовата, но в целом дает базу того, как работает коллаборативная фильтрация.
А чтобы посмотреть, как пользоваться этим методом "из коробки" на реальном датасете, можно глянуть вот этот ноутбук
Читайте статью, смотрите ноутбук, ставьте сердечки ❤️ на этот пост и пишите в комментариях, какой же все-таки фильм посмотреть админу сегодня вечером?😁
Один из самых простых способ порекомендовать что-то - коллаборативная фильтрация 🙂
Основное допущение метода состоит в том, что те, кто одинаково оценивал какие-либо предметы в прошлом, склонны давать похожие оценки другим предметам и в будущем.
Есть два подхода к коллаборативной фильтрации:
1. User-based – ищутся похожие пользователи
2. Item-based – ищутся похожие продукты
Глобально алгоритм такой:
1. Найти, насколько другие пользователи (продукты) в базе данных похожи на данного пользователя (продукт).
2. По оценкам других пользователей (продуктов) предсказать, какую оценку даст данный пользователь данному продукту, учитывая с большим весом тех пользователей (продукты), которые больше похожи на данный.
Эта статья хоть и старовата, но в целом дает базу того, как работает коллаборативная фильтрация.
А чтобы посмотреть, как пользоваться этим методом "из коробки" на реальном датасете, можно глянуть вот этот ноутбук
Читайте статью, смотрите ноутбук, ставьте сердечки ❤️ на этот пост и пишите в комментариях, какой же все-таки фильм посмотреть админу сегодня вечером?😁
{kind=link}
❤27🔥6😁5👍4
🛠 PCA - метод главных компонент
Иногда признаки в датасете довольно сильно зависят друг от друга, и их одновременное наличие избыточно. В таком случае можно выразить несколько признаков через один, и работать уже с более простой моделью.
Конечно, избежать потерь информации, скорее всего, не удастся, но минимизировать ее поможет метод PCA.
Чтобы понять, как он работает, можно посмотреть видео от StatQuest:
– [ENG] PCA Main Ideas in only 5 min - для тех, кто хочет вспомнить/понять основные идеи PCA
– [ENG] PCA Step-by-Step - тут метод главных компонент разбирается подробнее
– [ENG] 3 Practical Tips for PCA - прикладные советы по использованию PCA
Почитать про PCA можно в хендбуке от Яндекса, тут же можно посмотреть, как это все выглядит в Python
А если вам нужна сложная теория, можно почитать вот эту статью про PCA. Она хоть и немного старовата, но все равно дает хорошую теоретическую базу 🤓
И если дочитали до конца, обязательно ставьте сердечки ❤️ на этот пост)!
Иногда признаки в датасете довольно сильно зависят друг от друга, и их одновременное наличие избыточно. В таком случае можно выразить несколько признаков через один, и работать уже с более простой моделью.
Конечно, избежать потерь информации, скорее всего, не удастся, но минимизировать ее поможет метод PCA.
Чтобы понять, как он работает, можно посмотреть видео от StatQuest:
– [ENG] PCA Main Ideas in only 5 min - для тех, кто хочет вспомнить/понять основные идеи PCA
– [ENG] PCA Step-by-Step - тут метод главных компонент разбирается подробнее
– [ENG] 3 Practical Tips for PCA - прикладные советы по использованию PCA
Почитать про PCA можно в хендбуке от Яндекса, тут же можно посмотреть, как это все выглядит в Python
А если вам нужна сложная теория, можно почитать вот эту статью про PCA. Она хоть и немного старовата, но все равно дает хорошую теоретическую базу 🤓
YouTube
StatQuest: PCA main ideas in only 5 minutes!!!
The main ideas behind PCA are actually super simple and that means it's easy to interpret a PCA plot: Samples that are correlated will cluster together apart from samples that are not correlated with them. In this video, I walk through the ideas so that you…
❤65🔥5🤩2👍1
🔽 Подборка материалов про градиентный спуск
Зачастую задачи машинного обучения формулируются таким образом, что «веса» модели, которую мы строим, возникают, как решение оптимизационной задачи. И чтобы подобрать оптимальные веса, используется градиент функции потерь
Если вы не знакомы с градиентным спуском:
– Коротенькая лекция про градиентный спуск от МФТИ
– Лекция про линейную регрессию и градиентный спуск от Евгения Соколова, ВШЭ
– [ENG] Видео от StatQuest
Если хотите погрузиться в теорию:
– Статья-обзор градиентных методов в задачах математической оптимизации
– Хендбук с разбором алгоритмов оптимизации от Яндекса, много формул!
Просто интересные материалы:
– Статья про применение градиентного спуска на реальной Земле, задача - "выйти на уровень моря с любой начальной позиции"
– [ENG] Интерактивные визуализации, в которых можно выбрать точку старта и шаг градиентного спуска:
- На двумерном графике
- На трехмерном графике
Зачастую задачи машинного обучения формулируются таким образом, что «веса» модели, которую мы строим, возникают, как решение оптимизационной задачи. И чтобы подобрать оптимальные веса, используется градиент функции потерь
Градиент функции - это вектор, показывающий направление наибольшего возрастания функции, координатами которого являются частные производные этой функции по всем её переменным
Если вы не знакомы с градиентным спуском:
– Коротенькая лекция про градиентный спуск от МФТИ
– Лекция про линейную регрессию и градиентный спуск от Евгения Соколова, ВШЭ
– [ENG] Видео от StatQuest
Если хотите погрузиться в теорию:
– Статья-обзор градиентных методов в задачах математической оптимизации
– Хендбук с разбором алгоритмов оптимизации от Яндекса, много формул!
Просто интересные материалы:
– Статья про применение градиентного спуска на реальной Земле, задача - "выйти на уровень моря с любой начальной позиции"
– [ENG] Интерактивные визуализации, в которых можно выбрать точку старта и шаг градиентного спуска:
- На двумерном графике
- На трехмерном графике
{kind=link}
❤35👍5🔥5
🟦🟦🟦🟫 Серия видео от 3b1b про нейронные сети
3Blue1Brown - восхитительный канал с математическими анимациями. (Кстати, называется он так, потому что у автора гетерохромия: правый глаз на 3/4 голубой и на 1/4 карий). Если какая-то тема в матане/линале/теорвере вам неясна - стоит поискать её на этом канале, чтобы поймать интуитивное понимание
Один из плейлистов 3b1b - серия видео про Deep Learning. Тут автор наглядно объясняет основы работы нейронных сетей на примере нейросети для задачи распознавания цифр.
Вот переводы роликов, их оригиналы можно найти на вышеупомянутом канале:
– Что же такое нейронная сеть? – понятие нейрона, что означают связи между нейронами
– Градиентный спуск: как учатся нейронные сети – как обучается нейросеть, и почему зачастую мы не можем интерпретировать работу слоёв
– В чем на самом деле заключается метод обратного распространения? – метод обратного распространения интуитивно, что такое стохастический градиентный спуск
– Формулы обратного распространения - метод обратного распространения формально (но все равно интересно!)
Ставьте сердечки ❤️, если знаете и любите канал 3blue1brown, и огоньки 🔥, если слышите про него первый раз (обязательно зайдите и посмотрите!)
3Blue1Brown - восхитительный канал с математическими анимациями. (Кстати, называется он так, потому что у автора гетерохромия: правый глаз на 3/4 голубой и на 1/4 карий). Если какая-то тема в матане/линале/теорвере вам неясна - стоит поискать её на этом канале, чтобы поймать интуитивное понимание
Один из плейлистов 3b1b - серия видео про Deep Learning. Тут автор наглядно объясняет основы работы нейронных сетей на примере нейросети для задачи распознавания цифр.
Вот переводы роликов, их оригиналы можно найти на вышеупомянутом канале:
– Что же такое нейронная сеть? – понятие нейрона, что означают связи между нейронами
– Градиентный спуск: как учатся нейронные сети – как обучается нейросеть, и почему зачастую мы не можем интерпретировать работу слоёв
– В чем на самом деле заключается метод обратного распространения? – метод обратного распространения интуитивно, что такое стохастический градиентный спуск
– Формулы обратного распространения - метод обратного распространения формально (но все равно интересно!)
Ставьте сердечки ❤️, если знаете и любите канал 3blue1brown, и огоньки 🔥, если слышите про него первый раз (обязательно зайдите и посмотрите!)
YouTube
[DeepLearning | видео 1] Что же такое нейронная сеть?
Оригинальная запись: https://www.youtube.com/watch?v=aircAruvnKk
❤45🔥13👍1
📊 [ENG]Каталог графиков и диаграмм
У нас уже был пост про визуализации, хотим поделиться еще одним классным сайтом, на котором собраны различные способы визуализации данных.
– Можно искать подходящие визуализации по функции, которую должен выполнять график
– К каждому графику имеется описание – как его стоит интерпретировать
– Для каждого графика есть список инструментов, с помощью которых можно его создать, и ссылки на документацию к ним
Если хотите больше постов по датавизу, ставьте огонёчки!🔥
У нас уже был пост про визуализации, хотим поделиться еще одним классным сайтом, на котором собраны различные способы визуализации данных.
– Можно искать подходящие визуализации по функции, которую должен выполнять график
– К каждому графику имеется описание – как его стоит интерпретировать
– Для каждого графика есть список инструментов, с помощью которых можно его создать, и ссылки на документацию к ним
Если хотите больше постов по датавизу, ставьте огонёчки!🔥
{kind=link}
🔥46❤🔥5❤2
📈 Освежите знания по статистике
🐺🐺🐺
На канале LEFT JOIN (с создателем которого у нас, кстати, есть интервью) есть замечательная рубрика #основы_статистики, с помощью которой можно освежить в памяти понятия из статистики на конкретных примерах
Вот посты из этой рубрики:
– Основные понятия статистики
– Центральная предельная теорема
– Что такое p-value и как его считать
– T-статистика на примере
– Корреляция, ковариация
– Линейная регрессия
– Дисперсионный анализ
Если у вас не было курса по статистике, то помимо этих постов, конечно, лучше пройти какой-нибудь из полноценных бесплатных курсов, например, из нашей подборки🙂
Читайте публикации и ставьте сердечки ❤️, если было полезно
Статистика, возможно, знает все, но ее знают не все.
🐺🐺🐺
На канале LEFT JOIN (с создателем которого у нас, кстати, есть интервью) есть замечательная рубрика #основы_статистики, с помощью которой можно освежить в памяти понятия из статистики на конкретных примерах
Вот посты из этой рубрики:
– Основные понятия статистики
– Центральная предельная теорема
– Что такое p-value и как его считать
– T-статистика на примере
– Корреляция, ковариация
– Линейная регрессия
– Дисперсионный анализ
Если у вас не было курса по статистике, то помимо этих постов, конечно, лучше пройти какой-нибудь из полноценных бесплатных курсов, например, из нашей подборки🙂
Читайте публикации и ставьте сердечки ❤️, если было полезно
Telegram
LEFT JOIN
Понятно про анализ данных, технологии, нейросети и, конечно, SQL.
Услуги — leftjoin.ru
Курсы по аналитике — https://stepik.org/users/431992492
Автор — @valiotti
Реклама — @valiotti
Перечень РКН: https://tapthe.link/PpkTHavwS
Услуги — leftjoin.ru
Курсы по аналитике — https://stepik.org/users/431992492
Автор — @valiotti
Реклама — @valiotti
Перечень РКН: https://tapthe.link/PpkTHavwS
❤40🔥5❤🔥4👍1
Итоги 2023 и планы на 2024!
Спасибо всем, кто участвовал в жизни нашего сообщества в прошедшем году! И отдельное спасибо тем, кто пришёл к нам недавно - мы точно дадим качественный контент для вас 🙂
Итоги 2023:
1. Значимо выросли: по итогу года у нас практически +2.5k подписчиков, 725k просмотров и 20k+ пересылок! Последнее радует больше всего - для нас это означает, что контент для вас полезен и вы сохраняете его и делитесь им 🙂
2. Расширили штат! Теперь у меня (Рома Васильев, @RAVasiliev) есть помощник Олег, который позволяет значимо ускорить подготовку контента. Огромный респект Олегу!
Планы на 2024:
1. Расти! Ставим амбициозные цели - вырасти до 15к подписчиков, сделать 1.2M+ просмотров.
2. Запускать серьёзные образовательные проекты. Тут у нас есть куча планов: планируем сделать как минимум пару митапов и запустить еще один проект, который позволит вам быстро качать свою карьеру в Data Science!
3. Делать всё более и более качественный и полезный контент для вас!
Ставьте ❤️ если этот канал помогает вам совершенствовать свои навыки в DS и узнавать новое!)
И следите за контентом, здесь будет много чего интересного!
Спасибо всем, кто участвовал в жизни нашего сообщества в прошедшем году! И отдельное спасибо тем, кто пришёл к нам недавно - мы точно дадим качественный контент для вас 🙂
Итоги 2023:
1. Значимо выросли: по итогу года у нас практически +2.5k подписчиков, 725k просмотров и 20k+ пересылок! Последнее радует больше всего - для нас это означает, что контент для вас полезен и вы сохраняете его и делитесь им 🙂
2. Расширили штат! Теперь у меня (Рома Васильев, @RAVasiliev) есть помощник Олег, который позволяет значимо ускорить подготовку контента. Огромный респект Олегу!
Планы на 2024:
1. Расти! Ставим амбициозные цели - вырасти до 15к подписчиков, сделать 1.2M+ просмотров.
2. Запускать серьёзные образовательные проекты. Тут у нас есть куча планов: планируем сделать как минимум пару митапов и запустить еще один проект, который позволит вам быстро качать свою карьеру в Data Science!
3. Делать всё более и более качественный и полезный контент для вас!
Ставьте ❤️ если этот канал помогает вам совершенствовать свои навыки в DS и узнавать новое!)
И следите за контентом, здесь будет много чего интересного!
{kind=link}
❤59👍11
📹 Паттерны решения алгоритмических задач
В некоторых крупных компаниях присутствует такая практика, как алгоритмическое собеседование. На нем аналитикам обычно задают одну-две задачи уровня easy-medium с LeetCode.
Причем большинство задач имеют похожие подходы к решению – два указателя, скользящее окно, префиксные суммы, хэшмапы и т. д.
Недавно нашли классный плейлист, который поможет видеть паттерны решения алгозадач.
В идеале смотреть условие задачи, ставить видео на паузу, пытаться решить самому, и только потом уже смотреть решение задачи в видео
А ещё у Яндекса осенью прошли тренировки по алгоритмам 4.0, вот пост с подборкой полезных материалов оттуда
Если хотите больше постов про алгоритмы - ставьте огонёчки! 🔥
В некоторых крупных компаниях присутствует такая практика, как алгоритмическое собеседование. На нем аналитикам обычно задают одну-две задачи уровня easy-medium с LeetCode.
Причем большинство задач имеют похожие подходы к решению – два указателя, скользящее окно, префиксные суммы, хэшмапы и т. д.
Недавно нашли классный плейлист, который поможет видеть паттерны решения алгозадач.
В идеале смотреть условие задачи, ставить видео на паузу, пытаться решить самому, и только потом уже смотреть решение задачи в видео
А ещё у Яндекса осенью прошли тренировки по алгоритмам 4.0, вот пост с подборкой полезных материалов оттуда
Если хотите больше постов про алгоритмы - ставьте огонёчки! 🔥
YouTube
Мок собеседование на алгоритмы – Влад Тен – Find duplicates
Приходи на день открытых дверей, получи полезные материалы и задай вопрос выпускнику: https://go.elbrusboot.camp/dod_razrabs
Приходи на мастер-класс попрактиковаться в кодинге: https://go.elbrusboot.camp/mk_razrabs
Подпишись на ТГ: кодинг, IT-новости, смена…
Приходи на мастер-класс попрактиковаться в кодинге: https://go.elbrusboot.camp/mk_razrabs
Подпишись на ТГ: кодинг, IT-новости, смена…
🔥60👍10❤5