
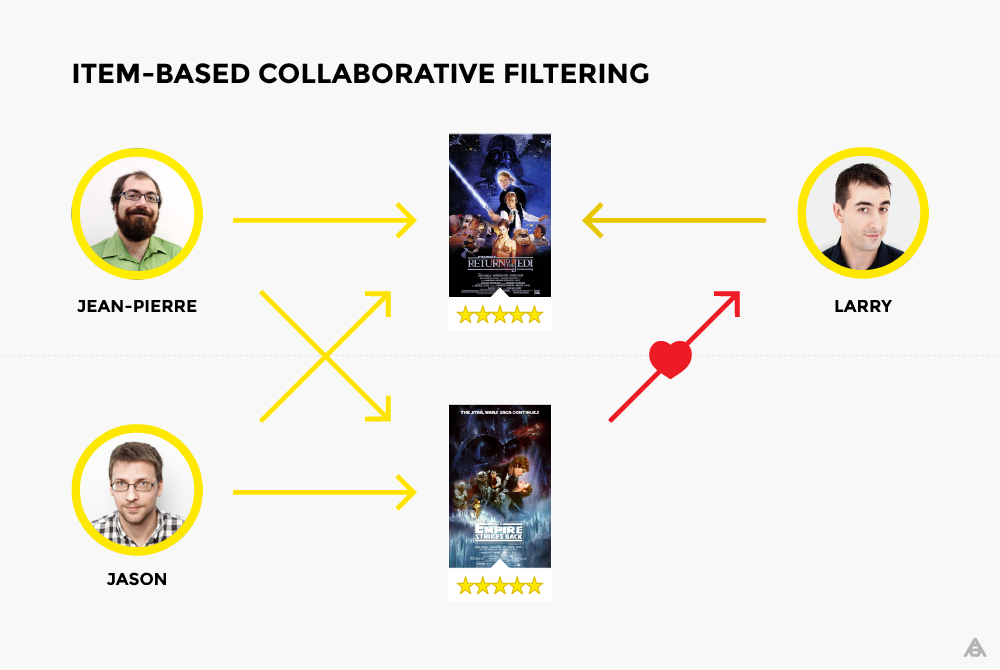
🎞 Порекомендуйте, пожалуйста, фильм на вечер
Один из самых простых способ порекомендовать что-то - коллаборативная фильтрация 🙂
Есть два подхода к коллаборативной фильтрации:
1. User-based – ищутся похожие пользователи
2. Item-based – ищутся похожие продукты
Глобально алгоритм такой:
1. Найти, насколько другие пользователи (продукты) в базе данных похожи на данного пользователя (продукт).
2. По оценкам других пользователей (продуктов) предсказать, какую оценку даст данный пользователь данному продукту, учитывая с большим весом тех пользователей (продукты), которые больше похожи на данный.
Эта статья хоть и старовата, но в целом дает базу того, как работает коллаборативная фильтрация.
А чтобы посмотреть, как пользоваться этим методом "из коробки" на реальном датасете, можно глянуть вот этот ноутбук
Читайте статью, смотрите ноутбук, ставьте сердечки ❤️ на этот пост и пишите в комментариях, какой же все-таки фильм посмотреть админу сегодня вечером?😁
Один из самых простых способ порекомендовать что-то - коллаборативная фильтрация 🙂
Основное допущение метода состоит в том, что те, кто одинаково оценивал какие-либо предметы в прошлом, склонны давать похожие оценки другим предметам и в будущем.
Есть два подхода к коллаборативной фильтрации:
1. User-based – ищутся похожие пользователи
2. Item-based – ищутся похожие продукты
Глобально алгоритм такой:
1. Найти, насколько другие пользователи (продукты) в базе данных похожи на данного пользователя (продукт).
2. По оценкам других пользователей (продуктов) предсказать, какую оценку даст данный пользователь данному продукту, учитывая с большим весом тех пользователей (продукты), которые больше похожи на данный.
Эта статья хоть и старовата, но в целом дает базу того, как работает коллаборативная фильтрация.
А чтобы посмотреть, как пользоваться этим методом "из коробки" на реальном датасете, можно глянуть вот этот ноутбук
Читайте статью, смотрите ноутбук, ставьте сердечки ❤️ на этот пост и пишите в комментариях, какой же все-таки фильм посмотреть админу сегодня вечером?😁
{kind=link}
❤27🔥6😁5👍4
🛠 PCA - метод главных компонент
Иногда признаки в датасете довольно сильно зависят друг от друга, и их одновременное наличие избыточно. В таком случае можно выразить несколько признаков через один, и работать уже с более простой моделью.
Конечно, избежать потерь информации, скорее всего, не удастся, но минимизировать ее поможет метод PCA.
Чтобы понять, как он работает, можно посмотреть видео от StatQuest:
– [ENG] PCA Main Ideas in only 5 min - для тех, кто хочет вспомнить/понять основные идеи PCA
– [ENG] PCA Step-by-Step - тут метод главных компонент разбирается подробнее
– [ENG] 3 Practical Tips for PCA - прикладные советы по использованию PCA
Почитать про PCA можно в хендбуке от Яндекса, тут же можно посмотреть, как это все выглядит в Python
А если вам нужна сложная теория, можно почитать вот эту статью про PCA. Она хоть и немного старовата, но все равно дает хорошую теоретическую базу 🤓
И если дочитали до конца, обязательно ставьте сердечки ❤️ на этот пост)!
Иногда признаки в датасете довольно сильно зависят друг от друга, и их одновременное наличие избыточно. В таком случае можно выразить несколько признаков через один, и работать уже с более простой моделью.
Конечно, избежать потерь информации, скорее всего, не удастся, но минимизировать ее поможет метод PCA.
Чтобы понять, как он работает, можно посмотреть видео от StatQuest:
– [ENG] PCA Main Ideas in only 5 min - для тех, кто хочет вспомнить/понять основные идеи PCA
– [ENG] PCA Step-by-Step - тут метод главных компонент разбирается подробнее
– [ENG] 3 Practical Tips for PCA - прикладные советы по использованию PCA
Почитать про PCA можно в хендбуке от Яндекса, тут же можно посмотреть, как это все выглядит в Python
А если вам нужна сложная теория, можно почитать вот эту статью про PCA. Она хоть и немного старовата, но все равно дает хорошую теоретическую базу 🤓
YouTube
StatQuest: PCA main ideas in only 5 minutes!!!
The main ideas behind PCA are actually super simple and that means it's easy to interpret a PCA plot: Samples that are correlated will cluster together apart from samples that are not correlated with them. In this video, I walk through the ideas so that you…
❤65🔥5🤩2👍1
🔽 Подборка материалов про градиентный спуск
Зачастую задачи машинного обучения формулируются таким образом, что «веса» модели, которую мы строим, возникают, как решение оптимизационной задачи. И чтобы подобрать оптимальные веса, используется градиент функции потерь
Если вы не знакомы с градиентным спуском:
– Коротенькая лекция про градиентный спуск от МФТИ
– Лекция про линейную регрессию и градиентный спуск от Евгения Соколова, ВШЭ
– [ENG] Видео от StatQuest
Если хотите погрузиться в теорию:
– Статья-обзор градиентных методов в задачах математической оптимизации
– Хендбук с разбором алгоритмов оптимизации от Яндекса, много формул!
Просто интересные материалы:
– Статья про применение градиентного спуска на реальной Земле, задача - "выйти на уровень моря с любой начальной позиции"
– [ENG] Интерактивные визуализации, в которых можно выбрать точку старта и шаг градиентного спуска:
- На двумерном графике
- На трехмерном графике
Зачастую задачи машинного обучения формулируются таким образом, что «веса» модели, которую мы строим, возникают, как решение оптимизационной задачи. И чтобы подобрать оптимальные веса, используется градиент функции потерь
Градиент функции - это вектор, показывающий направление наибольшего возрастания функции, координатами которого являются частные производные этой функции по всем её переменным
Если вы не знакомы с градиентным спуском:
– Коротенькая лекция про градиентный спуск от МФТИ
– Лекция про линейную регрессию и градиентный спуск от Евгения Соколова, ВШЭ
– [ENG] Видео от StatQuest
Если хотите погрузиться в теорию:
– Статья-обзор градиентных методов в задачах математической оптимизации
– Хендбук с разбором алгоритмов оптимизации от Яндекса, много формул!
Просто интересные материалы:
– Статья про применение градиентного спуска на реальной Земле, задача - "выйти на уровень моря с любой начальной позиции"
– [ENG] Интерактивные визуализации, в которых можно выбрать точку старта и шаг градиентного спуска:
- На двумерном графике
- На трехмерном графике
{kind=link}
❤35👍5🔥5
🟦🟦🟦🟫 Серия видео от 3b1b про нейронные сети
3Blue1Brown - восхитительный канал с математическими анимациями. (Кстати, называется он так, потому что у автора гетерохромия: правый глаз на 3/4 голубой и на 1/4 карий). Если какая-то тема в матане/линале/теорвере вам неясна - стоит поискать её на этом канале, чтобы поймать интуитивное понимание
Один из плейлистов 3b1b - серия видео про Deep Learning. Тут автор наглядно объясняет основы работы нейронных сетей на примере нейросети для задачи распознавания цифр.
Вот переводы роликов, их оригиналы можно найти на вышеупомянутом канале:
– Что же такое нейронная сеть? – понятие нейрона, что означают связи между нейронами
– Градиентный спуск: как учатся нейронные сети – как обучается нейросеть, и почему зачастую мы не можем интерпретировать работу слоёв
– В чем на самом деле заключается метод обратного распространения? – метод обратного распространения интуитивно, что такое стохастический градиентный спуск
– Формулы обратного распространения - метод обратного распространения формально (но все равно интересно!)
Ставьте сердечки ❤️, если знаете и любите канал 3blue1brown, и огоньки 🔥, если слышите про него первый раз (обязательно зайдите и посмотрите!)
3Blue1Brown - восхитительный канал с математическими анимациями. (Кстати, называется он так, потому что у автора гетерохромия: правый глаз на 3/4 голубой и на 1/4 карий). Если какая-то тема в матане/линале/теорвере вам неясна - стоит поискать её на этом канале, чтобы поймать интуитивное понимание
Один из плейлистов 3b1b - серия видео про Deep Learning. Тут автор наглядно объясняет основы работы нейронных сетей на примере нейросети для задачи распознавания цифр.
Вот переводы роликов, их оригиналы можно найти на вышеупомянутом канале:
– Что же такое нейронная сеть? – понятие нейрона, что означают связи между нейронами
– Градиентный спуск: как учатся нейронные сети – как обучается нейросеть, и почему зачастую мы не можем интерпретировать работу слоёв
– В чем на самом деле заключается метод обратного распространения? – метод обратного распространения интуитивно, что такое стохастический градиентный спуск
– Формулы обратного распространения - метод обратного распространения формально (но все равно интересно!)
Ставьте сердечки ❤️, если знаете и любите канал 3blue1brown, и огоньки 🔥, если слышите про него первый раз (обязательно зайдите и посмотрите!)
YouTube
[DeepLearning | видео 1] Что же такое нейронная сеть?
Оригинальная запись: https://www.youtube.com/watch?v=aircAruvnKk
❤45🔥13👍1
📊 [ENG]Каталог графиков и диаграмм
У нас уже был пост про визуализации, хотим поделиться еще одним классным сайтом, на котором собраны различные способы визуализации данных.
– Можно искать подходящие визуализации по функции, которую должен выполнять график
– К каждому графику имеется описание – как его стоит интерпретировать
– Для каждого графика есть список инструментов, с помощью которых можно его создать, и ссылки на документацию к ним
Если хотите больше постов по датавизу, ставьте огонёчки!🔥
У нас уже был пост про визуализации, хотим поделиться еще одним классным сайтом, на котором собраны различные способы визуализации данных.
– Можно искать подходящие визуализации по функции, которую должен выполнять график
– К каждому графику имеется описание – как его стоит интерпретировать
– Для каждого графика есть список инструментов, с помощью которых можно его создать, и ссылки на документацию к ним
Если хотите больше постов по датавизу, ставьте огонёчки!🔥
{kind=link}
🔥46❤🔥5❤2
📈 Освежите знания по статистике
🐺🐺🐺
На канале LEFT JOIN (с создателем которого у нас, кстати, есть интервью) есть замечательная рубрика #основы_статистики, с помощью которой можно освежить в памяти понятия из статистики на конкретных примерах
Вот посты из этой рубрики:
– Основные понятия статистики
– Центральная предельная теорема
– Что такое p-value и как его считать
– T-статистика на примере
– Корреляция, ковариация
– Линейная регрессия
– Дисперсионный анализ
Если у вас не было курса по статистике, то помимо этих постов, конечно, лучше пройти какой-нибудь из полноценных бесплатных курсов, например, из нашей подборки🙂
Читайте публикации и ставьте сердечки ❤️, если было полезно
Статистика, возможно, знает все, но ее знают не все.
🐺🐺🐺
На канале LEFT JOIN (с создателем которого у нас, кстати, есть интервью) есть замечательная рубрика #основы_статистики, с помощью которой можно освежить в памяти понятия из статистики на конкретных примерах
Вот посты из этой рубрики:
– Основные понятия статистики
– Центральная предельная теорема
– Что такое p-value и как его считать
– T-статистика на примере
– Корреляция, ковариация
– Линейная регрессия
– Дисперсионный анализ
Если у вас не было курса по статистике, то помимо этих постов, конечно, лучше пройти какой-нибудь из полноценных бесплатных курсов, например, из нашей подборки🙂
Читайте публикации и ставьте сердечки ❤️, если было полезно
Telegram
LEFT JOIN
Понятно про анализ данных, технологии, нейросети и, конечно, SQL.
Услуги — leftjoin.ru
Курсы по аналитике — https://stepik.org/users/431992492
Автор — @valiotti
Реклама — @valiotti
Перечень РКН: https://tapthe.link/PpkTHavwS
Услуги — leftjoin.ru
Курсы по аналитике — https://stepik.org/users/431992492
Автор — @valiotti
Реклама — @valiotti
Перечень РКН: https://tapthe.link/PpkTHavwS
❤40🔥5❤🔥4👍1
Итоги 2023 и планы на 2024!
Спасибо всем, кто участвовал в жизни нашего сообщества в прошедшем году! И отдельное спасибо тем, кто пришёл к нам недавно - мы точно дадим качественный контент для вас 🙂
Итоги 2023:
1. Значимо выросли: по итогу года у нас практически +2.5k подписчиков, 725k просмотров и 20k+ пересылок! Последнее радует больше всего - для нас это означает, что контент для вас полезен и вы сохраняете его и делитесь им 🙂
2. Расширили штат! Теперь у меня (Рома Васильев, @RAVasiliev) есть помощник Олег, который позволяет значимо ускорить подготовку контента. Огромный респект Олегу!
Планы на 2024:
1. Расти! Ставим амбициозные цели - вырасти до 15к подписчиков, сделать 1.2M+ просмотров.
2. Запускать серьёзные образовательные проекты. Тут у нас есть куча планов: планируем сделать как минимум пару митапов и запустить еще один проект, который позволит вам быстро качать свою карьеру в Data Science!
3. Делать всё более и более качественный и полезный контент для вас!
Ставьте ❤️ если этот канал помогает вам совершенствовать свои навыки в DS и узнавать новое!)
И следите за контентом, здесь будет много чего интересного!
Спасибо всем, кто участвовал в жизни нашего сообщества в прошедшем году! И отдельное спасибо тем, кто пришёл к нам недавно - мы точно дадим качественный контент для вас 🙂
Итоги 2023:
1. Значимо выросли: по итогу года у нас практически +2.5k подписчиков, 725k просмотров и 20k+ пересылок! Последнее радует больше всего - для нас это означает, что контент для вас полезен и вы сохраняете его и делитесь им 🙂
2. Расширили штат! Теперь у меня (Рома Васильев, @RAVasiliev) есть помощник Олег, который позволяет значимо ускорить подготовку контента. Огромный респект Олегу!
Планы на 2024:
1. Расти! Ставим амбициозные цели - вырасти до 15к подписчиков, сделать 1.2M+ просмотров.
2. Запускать серьёзные образовательные проекты. Тут у нас есть куча планов: планируем сделать как минимум пару митапов и запустить еще один проект, который позволит вам быстро качать свою карьеру в Data Science!
3. Делать всё более и более качественный и полезный контент для вас!
Ставьте ❤️ если этот канал помогает вам совершенствовать свои навыки в DS и узнавать новое!)
И следите за контентом, здесь будет много чего интересного!
{kind=link}
❤59👍11
📹 Паттерны решения алгоритмических задач
В некоторых крупных компаниях присутствует такая практика, как алгоритмическое собеседование. На нем аналитикам обычно задают одну-две задачи уровня easy-medium с LeetCode.
Причем большинство задач имеют похожие подходы к решению – два указателя, скользящее окно, префиксные суммы, хэшмапы и т. д.
Недавно нашли классный плейлист, который поможет видеть паттерны решения алгозадач.
В идеале смотреть условие задачи, ставить видео на паузу, пытаться решить самому, и только потом уже смотреть решение задачи в видео
А ещё у Яндекса осенью прошли тренировки по алгоритмам 4.0, вот пост с подборкой полезных материалов оттуда
Если хотите больше постов про алгоритмы - ставьте огонёчки! 🔥
В некоторых крупных компаниях присутствует такая практика, как алгоритмическое собеседование. На нем аналитикам обычно задают одну-две задачи уровня easy-medium с LeetCode.
Причем большинство задач имеют похожие подходы к решению – два указателя, скользящее окно, префиксные суммы, хэшмапы и т. д.
Недавно нашли классный плейлист, который поможет видеть паттерны решения алгозадач.
В идеале смотреть условие задачи, ставить видео на паузу, пытаться решить самому, и только потом уже смотреть решение задачи в видео
А ещё у Яндекса осенью прошли тренировки по алгоритмам 4.0, вот пост с подборкой полезных материалов оттуда
Если хотите больше постов про алгоритмы - ставьте огонёчки! 🔥
YouTube
Мок собеседование на алгоритмы – Влад Тен – Find duplicates
Приходи на день открытых дверей, получи полезные материалы и задай вопрос выпускнику: https://go.elbrusboot.camp/dod_razrabs
Приходи на мастер-класс попрактиковаться в кодинге: https://go.elbrusboot.camp/mk_razrabs
Подпишись на ТГ: кодинг, IT-новости, смена…
Приходи на мастер-класс попрактиковаться в кодинге: https://go.elbrusboot.camp/mk_razrabs
Подпишись на ТГ: кодинг, IT-новости, смена…
🔥60👍10❤5
💘 Увеличить чувствительность А/В теста без смс и регистрации
Мы уже делали посты про CUPED:
1) Статья от аналитиков Авито
2) Выступление Валерия Бабушкина
Эти материалы классные, но могут быть сложноваты для новичка.
Недавно от аналитиков Х5 Group вышла новая статья про CUPED - прочитав которую, как будто, даже новичку станет понятно, что это за зверь такой.
Авторы дают не только интуитивное понимание метода, но и математическое обоснование, пример кода и советы по применению
Ставьте огоньки под этим постом (давайте наберём 50🔥), и обязательно читайте статью!
CUPED (Controlled-experiment Using Pre-Experiment Data) - техника увеличения чувствительности А/Б тестов за счет использования данных, полученных ранее
Мы уже делали посты про CUPED:
1) Статья от аналитиков Авито
2) Выступление Валерия Бабушкина
Эти материалы классные, но могут быть сложноваты для новичка.
Недавно от аналитиков Х5 Group вышла новая статья про CUPED - прочитав которую, как будто, даже новичку станет понятно, что это за зверь такой.
Авторы дают не только интуитивное понимание метода, но и математическое обоснование, пример кода и советы по применению
Ставьте огоньки под этим постом (давайте наберём 50🔥), и обязательно читайте статью!
Хабр
А/Б тестирование с CUPED: детальный разбор
Хабр, привет! Сегодня обсудим, как применять CUPED для повышения чувствительности А/Б тестов. Рассмотрим на простом примере принцип работы CUPED, покажем теоретически за счёт чего снижается дисперсия...
🔥54👍6❤3
👁 Мягкий вход в Computer Vision
Мы в SCiDS много пишем про классические алгоритмы машинного обучения. Но очень часто у нас спрашивают "А вот как зашарить DL?", "Хочу в NLP/CV - что читать?" и т.д. Решили писать про это больше 🙂
А тут у недавно вышло крутое видео от Бориса про то, что происходит в архитектурах Computer Vision моделей. Причём начинается всё с логистической регрессии, а заканчивается трансформерами. В общем, для первого погружения в CV (при условии что вы понимаете классическую машинку) - самое то.
[Ссылка на видео]
Накидывайте 🔥 если хотите больше постов про NLP/CV!
Мы в SCiDS много пишем про классические алгоритмы машинного обучения. Но очень часто у нас спрашивают "А вот как зашарить DL?", "Хочу в NLP/CV - что читать?" и т.д. Решили писать про это больше 🙂
А тут у недавно вышло крутое видео от Бориса про то, что происходит в архитектурах Computer Vision моделей. Причём начинается всё с логистической регрессии, а заканчивается трансформерами. В общем, для первого погружения в CV (при условии что вы понимаете классическую машинку) - самое то.
[Ссылка на видео]
Накидывайте 🔥 если хотите больше постов про NLP/CV!
YouTube
История архитектур Computer Vision моделей от AlexNet до ViT // Курс «Компьютерное зрение»
Как развивались архитектуры нейронных сетей для компьютерного зрения, какие были самые значимые повороты и какие модели можно взять ""с полки"" для практических задач сегодня.
Результаты урока:
- какая история развития мысли в Computer Vision
- какие…
Результаты урока:
- какая история развития мысли в Computer Vision
- какие…
🔥43❤🔥5❤2🤩2👍1
🌐 Как выйти за пределы юпитер ноутбука?
Большинство начинающих дата-саентистов разрабатывают модельки в юпитер ноутбуках. Но на практике, как правило, используют модели не в ноутбуках, а запускают скрипты из различных систем. Что же нужно для для этого делать?
Во-первых, для выхода из ноутбука нужно научиться создавать такой код, который запускается одним нажатием Run All. Впоследствии это уже можно сохранить в виде скрипта с расширением .py и работать с ним.
Далее есть два уровня выхода из ноутбука:
1. Запуск скриптов по расписанию
a) В unix-системах есть команда cron, которая позволяет регулярно запускать скрипты. В своём скрипте вы, соответственно, можете собирать актуальные данные, прогонять их через модель и отправлять эти данные туда, куда вам нужно.
Можно настроить cron как на локалхосте, так и на каком-нибудь удаленном сервере. Подробнее про cron можно почитать здесь
b) Можно делать регулярные операции с данными в скрипте с помощью библиотеки scheduler, закинув скрипт на Амверу/ Render/ какие-то подобные сервисы, где он будет крутиться
2. Запуск пайплайнов по расписанию
1) Apache Airflow - система, с помощью которой можно запускать пайплайны по расписанию: автоматически собирать данные, передавать в модель и что-то делать с выходными данными модели
2) MLFlow - запуск пайплайнов по расписанию + мониторинг (на смещение скора, на входные фичи и т. д.)
Про него и другие опенсорсные решения для MLOps на Хабре есть классная статья
Еще про продуктивизацию ml моделей есть классный плейлист, стоит посмотреть, если хотите разобраться в этой теме 🙂
Ставьте огоньки, если было полезно (наберем 70 🔥?) и пишите в комментариях, про что бы вам еще хотелось увидеть посты
Большинство начинающих дата-саентистов разрабатывают модельки в юпитер ноутбуках. Но на практике, как правило, используют модели не в ноутбуках, а запускают скрипты из различных систем. Что же нужно для для этого делать?
Во-первых, для выхода из ноутбука нужно научиться создавать такой код, который запускается одним нажатием Run All. Впоследствии это уже можно сохранить в виде скрипта с расширением .py и работать с ним.
Далее есть два уровня выхода из ноутбука:
1. Запуск скриптов по расписанию
a) В unix-системах есть команда cron, которая позволяет регулярно запускать скрипты. В своём скрипте вы, соответственно, можете собирать актуальные данные, прогонять их через модель и отправлять эти данные туда, куда вам нужно.
Можно настроить cron как на локалхосте, так и на каком-нибудь удаленном сервере. Подробнее про cron можно почитать здесь
b) Можно делать регулярные операции с данными в скрипте с помощью библиотеки scheduler, закинув скрипт на Амверу/ Render/ какие-то подобные сервисы, где он будет крутиться
2. Запуск пайплайнов по расписанию
1) Apache Airflow - система, с помощью которой можно запускать пайплайны по расписанию: автоматически собирать данные, передавать в модель и что-то делать с выходными данными модели
2) MLFlow - запуск пайплайнов по расписанию + мониторинг (на смещение скора, на входные фичи и т. д.)
Про него и другие опенсорсные решения для MLOps на Хабре есть классная статья
Еще про продуктивизацию ml моделей есть классный плейлист, стоит посмотреть, если хотите разобраться в этой теме 🙂
Ставьте огоньки, если было полезно (наберем 70 🔥?) и пишите в комментариях, про что бы вам еще хотелось увидеть посты
Хабр
Cron в Linux: история, использование и устройство
Классик писал, что счастливые часов не наблюдают. В те дикие времена ещё не было ни программистов, ни Unix, но в наши дни программисты знают твёрдо: вместо них за временем проследит cron. Утилиты...
🔥114👍11❤6🤩4
🔍 Поиск оптимальных гиперпараметров для модели
Гиперпараметры модели – это настройки, которые определяют как саму структуру модели, так и способ её обучения.
Например, у случайного леса они могут быть такими:
– Количество деревьев (n_estimators)
– Максимальная глубина деревьев (max_depth)
– Минимальное количество объектов в листе (min_samples_leaf)
– Максимальное количество признаков для разбиения (max_features)
Чтобы получить самую лучшую модель, нужно как-то подобрать эти гиперпараметры. Есть несколько способов:
🤪 «Тупой» перебор гиперпараметров
– Grid Search - просто перебор всевозможных комбинаций значений гиперпараметров
– Random Search - перебор случайных наборов гиперпараметров (в том случае, когда Grid Search слишком долгий)
🤓 «Умный» перебор гиперпараметров
– Bayesian Optimization - метод, который сочетает вероятностные модели с методами оптимизации для эффективного поиска оптимальных гиперпараметров
– Другие умные методы - реализованы, например, во фреймворке Optuna - библиотеке, которая представляет высокоуровневый интерфейс для оптимизации гиперпараметров
Причем иногда «тупой» рандомный перебор работает лучше, чем «умный» (так бывает, потому что рандомный может случайно найти глобальный минимум, а умный может зациклиться на локальном). Чтобы понять, что лучше подойдёт в вашем случае, можно попробовать оба способа
Подробнее про подбор гиперпараметров написано вот в этой статье, с примерами, инструментами и классными советами 🙂
Читайте статью и ставьте сердечки под этим постом!(наберем 70 ❤️?)
Гиперпараметры модели – это настройки, которые определяют как саму структуру модели, так и способ её обучения.
Например, у случайного леса они могут быть такими:
– Количество деревьев (n_estimators)
– Максимальная глубина деревьев (max_depth)
– Минимальное количество объектов в листе (min_samples_leaf)
– Максимальное количество признаков для разбиения (max_features)
Чтобы получить самую лучшую модель, нужно как-то подобрать эти гиперпараметры. Есть несколько способов:
🤪 «Тупой» перебор гиперпараметров
– Grid Search - просто перебор всевозможных комбинаций значений гиперпараметров
– Random Search - перебор случайных наборов гиперпараметров (в том случае, когда Grid Search слишком долгий)
🤓 «Умный» перебор гиперпараметров
– Bayesian Optimization - метод, который сочетает вероятностные модели с методами оптимизации для эффективного поиска оптимальных гиперпараметров
– Другие умные методы - реализованы, например, во фреймворке Optuna - библиотеке, которая представляет высокоуровневый интерфейс для оптимизации гиперпараметров
Причем иногда «тупой» рандомный перебор работает лучше, чем «умный» (так бывает, потому что рандомный может случайно найти глобальный минимум, а умный может зациклиться на локальном). Чтобы понять, что лучше подойдёт в вашем случае, можно попробовать оба способа
Подробнее про подбор гиперпараметров написано вот в этой статье, с примерами, инструментами и классными советами 🙂
Читайте статью и ставьте сердечки под этим постом!(наберем 70 ❤️?)
Хабр
Гиперпараметрический поиск и оптимизация моделей
При создании моделей машинного обучения существует одна важная составляющая, которая часто остается за кадром, но имеет решающее значение для достижения высокой производительности и точности — это...
❤82👍6🔥5🤩1
💼 Как быстро вспомнить основные идеи в ML перед собеседованием?
Если вы только начинаете карьеру, то на собеседованиях в DS вас точно будут спрашивать про то, как работают конкретные алгоритмы.
Какое-то время назад мы решили сделать серию видео для того, чтобы быстро вспомнить все ключевые идеи!
Пока что вышло не так много видео, но если хотите какое-то особенное - пишите в комментариях 🙂
1. Линейная регрессия. Что спросят на собеседовании? ч.1 - про основные идеи линейной регресии, предобработку признаков, fit-predict и регуляризацию
2. Линейная регрессия. Что внутри sklearn? Зачем градиентный спуск? Что спросят на собеседовании? ч.2 - про то, какие реализации линейной регрессии есть и как они работают под капотом
3. Функционалы потерь и метрики регрессии. Простым языком! - все базовые метрики и функционалы потерь регрессии в одном видео
4. Логистическая регрессия, самое простое объяснение! - как устроена логистическая регрессия, что оптимизирует и почему аппроксимирует вероятности.
Оставляйте 🔥 под видео, каждый из них приблизит момент выпуска следующих видео!)
Если вы только начинаете карьеру, то на собеседованиях в DS вас точно будут спрашивать про то, как работают конкретные алгоритмы.
Какое-то время назад мы решили сделать серию видео для того, чтобы быстро вспомнить все ключевые идеи!
Пока что вышло не так много видео, но если хотите какое-то особенное - пишите в комментариях 🙂
1. Линейная регрессия. Что спросят на собеседовании? ч.1 - про основные идеи линейной регресии, предобработку признаков, fit-predict и регуляризацию
2. Линейная регрессия. Что внутри sklearn? Зачем градиентный спуск? Что спросят на собеседовании? ч.2 - про то, какие реализации линейной регрессии есть и как они работают под капотом
3. Функционалы потерь и метрики регрессии. Простым языком! - все базовые метрики и функционалы потерь регрессии в одном видео
4. Логистическая регрессия, самое простое объяснение! - как устроена логистическая регрессия, что оптимизирует и почему аппроксимирует вероятности.
Оставляйте 🔥 под видео, каждый из них приблизит момент выпуска следующих видео!)
YouTube
Линейная регрессия. Что спросят на собеседовании? ч.1
0:00 - О чём видео, дисклеймер
0:39 - План видео
1:09 - Что такое линейная регрессия? Основные идеи и особенности алгоритма
2:57 - Нужно ли предобрабатывать признаки моя линейных моделей? Если да, то как?
4:57 - Что подразумевается под fit() и predict() в…
0:39 - План видео
1:09 - Что такое линейная регрессия? Основные идеи и особенности алгоритма
2:57 - Нужно ли предобрабатывать признаки моя линейных моделей? Если да, то как?
4:57 - Что подразумевается под fit() и predict() в…
🔥86❤12👍12❤🔥6
🐶 Пет-проекты для начинающего Data Scientistа
Во-первых, это позволит вам понять, действительно ли вы заинтересованы в этой сфере.
Во-вторых, точно прокачает ваши навыки.
Ну и в-третьих, его можно будет указать в резюме, если у вас не было опыта работы. Собеседующий точно заметит, если вы будете с энтузиазмом рассказывать про свои проекты
В идеале в вашем проекте должны быть затронуты все этапы работы с данными:
1. Получение данных:
- Можно спарсить данные, например, с помощью библиотек BeautifulSoup, Scrapy или Selenium (если под этим постом наберётся 100 сердечек ❤️, мы расскажем про парсинг подробнее)
- Можно поработать с какой-нибудь APIшкой для получения данных (например, с api ХедХантера для вакансий)
- Можно скачать датасет из открытых источников, например, с Kaggle или Google Dataset Search
2. Исследовательский анализ данных (EDA):
- Повизуализировать данные с помощью библиотек вроде Matplotlib, Seaborn или Plotly для нахождения закономерностей и аномалий
- Поприменять статистический анализ для понимания распределений и тестирования гипотез
3. Предобработка данных:
- Почистить данные от пропусков и выбросов
- Преобразовать типы данных, нормализировать и стандартизировать их
- Попробовать придумать новые признаки для повышения точности моделей
4. Построение моделей:
- Понять, какой алгоритм машинного обучения будет эффективнее в вашей задаче (от линейной регрессии до градиентного бустинга и глубокого обучения)
- Оптимизировать его гиперапараметры
5. Настройка регулярных процессов (про это, кстати, у нас был пост):
- Автоматизировать сбор и обновление данных через скрипты
- Настроить автоматическое переобучение моделей с новыми данными
6. Работа с большими данными:
- Попробовать поработать с Hadoop/Spark для обработки большого объема данных (если под этим постом наберётся 150 сердечек❤️, мы расскажем подробнее про MapReduce)
- Понять, что в вашем проекте это совсем ни к чему и использовать для хранения и обработки данных, например, PostgreSQL или MongoDB
7. Деплой модели:
- Юзануть Docker контейнеры для упаковки и деплоя моделей и приложений
- Познакомиться с облачными платформами, такими как AWS, Google Cloud или Azure для развертывания моделей
Будет очень классно, если идея проекта придет к вам в процессе решения какой-нибудь задачи из жизни. Если же идей нет, можно взять их отсюда:
– 10 проектов по data science для начинающих
– 36 идей для проектов по аналитике данных
(просто вбиваете в поиск “идеи пет-проекта для data scientistа” 😁)
Ставьте сердечки❤️ под этим постом, если было полезно, и начинайте делать свой первый пет-проект, если еще не начали!
Pet-project
- это небольшой личный проект в любой отрасли для портфолио и/или собственного удовольствия. Начинающему дата саентисту почти что необходимо сделать какой-нибудь
(пусть даже совсем небольшой)
пет-проект
Во-первых, это позволит вам понять, действительно ли вы заинтересованы в этой сфере.
Во-вторых, точно прокачает ваши навыки.
Ну и в-третьих, его можно будет указать в резюме, если у вас не было опыта работы. Собеседующий точно заметит, если вы будете с энтузиазмом рассказывать про свои проекты
В идеале в вашем проекте должны быть затронуты все этапы работы с данными:
1. Получение данных:
- Можно спарсить данные, например, с помощью библиотек BeautifulSoup, Scrapy или Selenium (если под этим постом наберётся 100 сердечек ❤️, мы расскажем про парсинг подробнее)
- Можно поработать с какой-нибудь APIшкой для получения данных (например, с api ХедХантера для вакансий)
- Можно скачать датасет из открытых источников, например, с Kaggle или Google Dataset Search
2. Исследовательский анализ данных (EDA):
- Повизуализировать данные с помощью библиотек вроде Matplotlib, Seaborn или Plotly для нахождения закономерностей и аномалий
- Поприменять статистический анализ для понимания распределений и тестирования гипотез
3. Предобработка данных:
- Почистить данные от пропусков и выбросов
- Преобразовать типы данных, нормализировать и стандартизировать их
- Попробовать придумать новые признаки для повышения точности моделей
4. Построение моделей:
- Понять, какой алгоритм машинного обучения будет эффективнее в вашей задаче (от линейной регрессии до градиентного бустинга и глубокого обучения)
- Оптимизировать его гиперапараметры
5. Настройка регулярных процессов (про это, кстати, у нас был пост):
- Автоматизировать сбор и обновление данных через скрипты
- Настроить автоматическое переобучение моделей с новыми данными
6. Работа с большими данными:
- Попробовать поработать с Hadoop/Spark для обработки большого объема данных (если под этим постом наберётся 150 сердечек❤️, мы расскажем подробнее про MapReduce)
- Понять, что в вашем проекте это совсем ни к чему и использовать для хранения и обработки данных, например, PostgreSQL или MongoDB
7. Деплой модели:
- Юзануть Docker контейнеры для упаковки и деплоя моделей и приложений
- Познакомиться с облачными платформами, такими как AWS, Google Cloud или Azure для развертывания моделей
Будет очень классно, если идея проекта придет к вам в процессе решения какой-нибудь задачи из жизни. Если же идей нет, можно взять их отсюда:
– 10 проектов по data science для начинающих
– 36 идей для проектов по аналитике данных
(просто вбиваете в поиск “идеи пет-проекта для data scientistа” 😁)
Ставьте сердечки❤️ под этим постом, если было полезно, и начинайте делать свой первый пет-проект, если еще не начали!
Хабр
Data Science Pet Projects. FAQ
Привет! Меня зовут Клоков Алексей, сегодня поговорим о пет-проектах по анализу данных. Идея написать эту статью родилась после многочисленных вопросов о личных проектах в сообществе Open Data Science...
❤234👍13🔥4
💼 Как научиться проходить собесы?
Лучший способ -проходить собесы. Ну, или смотреть как это делают другие 🙂
Вот Вадим не щадит себя, проходит их везде где можно и выкладывает записи!
Самые интересные видео с канала:
1. Собес на DS'a в Сбер
2. Собес на Senior DS'a в Райф
3. Как составить резюме программисту. Полный гайд
4. Полный гайд по собеседованию в IT — рабочий алгоритм
Подписывайтесь на Вадима, в его каналах можно найти много интересного 🙂
Куда идти: Tg, YouTube
Лучший способ -
Вот Вадим не щадит себя, проходит их везде где можно и выкладывает записи!
Самые интересные видео с канала:
1. Собес на DS'a в Сбер
2. Собес на Senior DS'a в Райф
3. Как составить резюме программисту. Полный гайд
4. Полный гайд по собеседованию в IT — рабочий алгоритм
Подписывайтесь на Вадима, в его каналах можно найти много интересного 🙂
Куда идти: Tg, YouTube
YouTube
Как составить резюме программисту. Полный гайд
https://offer.gernar.ru/?utm_source=youtube&utm_content=1ZBdnUKeIGg — ОФФЕР ПОД КЛЮЧ 🔑
Возможно-ли, сделать идеальное резюме начинающего программиста без опыта так, чтобы не облажаться на первых же шагах в поиске работы в IT? Да, это не просто возможно —…
Возможно-ли, сделать идеальное резюме начинающего программиста без опыта так, чтобы не облажаться на первых же шагах в поиске работы в IT? Да, это не просто возможно —…
🔥45👍10❤2❤🔥1😁1
💼 Вакансии в различные направления DS, Аналитики и ML
Наши друзья сделали канал с вакансиями для ребят всех уровней: от стажёров до лидов!
Чем он отличается от прочих подобных:
1. Заранее отметаются сомнительные компании и сомнительные вакансии
2. По каждой вакансии делается короткая выжимка, чтобы бытро понять надо оно вам или нет
3🌟. К каждой вакансии ребята цепляют подборку материалов по ней. Если компания малоизвестная - скажут где почитать про неё, если направление своеобразное - дадут статью/набор статей, которые позволят понять что происходит
В общем, ОЧЕНЬ рекомендуем подписаться на Your Dream Data Job!
Наши друзья сделали канал с вакансиями для ребят всех уровней: от стажёров до лидов!
Чем он отличается от прочих подобных:
1. Заранее отметаются сомнительные компании и сомнительные вакансии
2. По каждой вакансии делается короткая выжимка, чтобы бытро понять надо оно вам или нет
3🌟. К каждой вакансии ребята цепляют подборку материалов по ней. Если компания малоизвестная - скажут где почитать про неё, если направление своеобразное - дадут статью/набор статей, которые позволят понять что происходит
В общем, ОЧЕНЬ рекомендуем подписаться на Your Dream Data Job!
Telegram
Your Dream Data Job
Рассказываем про офигенные вакансии напрямую.
Чтобы понять позицию, к каждой вакансии даём полезные материалы для чтения!
Чтобы понять позицию, к каждой вакансии даём полезные материалы для чтения!
❤🔥11👍9❤7😁2
🐘 MapReduce - что это такое?
Если говорить по-простому, то MapReduce - это модель распределенных вычислений, которая необходима, чтобы считать то, что либо нужно делать быстрее, либо то, на что не хватает памяти (либо и то, и то)
Обычно системы MapReduce используются в больших компаниях, которым нужно обрабатывать петабайты данных. Самый распространенный фреймворк - Hadoop, но некоторые компании создают свои MapReduce системы (например, в Яндексе своя система называется Ыть)
Чтобы понять, что такое MapReduce, во-первых, советуем глянуть это видео [ENG]
А во-вторых, стоит по порядку прочитать эти две статьи, в которых автор (имхо) супер доступно, с примерами, объясняет, как устроена модель MapReduce:
– MapReduce без зауми, ч.1 - автор статьи рассказывает, как он, столкнувшись с задачей посчитать количество всех слов в Википедии, сам еще раз “придумал” MapReduce
– MapReduce без зауми, ч.2 - тут уже разбираются более-менее реальные SQL-ные операции
Если вы собираетесь работать в крупной IT-компании, вам нужно знать, что такое MapReduce. Поэтому смотрите видео, читайте статьи (раз, два) и оставляйте огонёчки 🔥 под этим постом, если он вам понравился))
Если говорить по-простому, то MapReduce - это модель распределенных вычислений, которая необходима, чтобы считать то, что либо нужно делать быстрее, либо то, на что не хватает памяти (либо и то, и то)
Обычно системы MapReduce используются в больших компаниях, которым нужно обрабатывать петабайты данных. Самый распространенный фреймворк - Hadoop, но некоторые компании создают свои MapReduce системы (например, в Яндексе своя система называется Ыть)
Чтобы понять, что такое MapReduce, во-первых, советуем глянуть это видео [ENG]
А во-вторых, стоит по порядку прочитать эти две статьи, в которых автор (имхо) супер доступно, с примерами, объясняет, как устроена модель MapReduce:
– MapReduce без зауми, ч.1 - автор статьи рассказывает, как он, столкнувшись с задачей посчитать количество всех слов в Википедии, сам еще раз “придумал” MapReduce
– MapReduce без зауми, ч.2 - тут уже разбираются более-менее реальные SQL-ные операции
Если вы собираетесь работать в крупной IT-компании, вам нужно знать, что такое MapReduce. Поэтому смотрите видео, читайте статьи (раз, два) и оставляйте огонёчки 🔥 под этим постом, если он вам понравился))
YouTube
What is MapReduce?
Building efficient data centers that can hold thousands of machines is hard enough. Programming thousands of machines is even harder. One approach pioneered by Google is known as MapReduce. MapReduce provides a programming model that simplifies programming…
🔥45👍11❤6😁2
Побеждаем рутину в Data Science: как перестать быть недопрограммистами и недоисследователями
Ребята из Альфы во главе с Женей написали клёвую статью, которая позволит отлично понять как устроена работа в Data Science.
Про что рассказывают в статье:
👨🏫 Причины возникновения рутины с точки зрения пользователя, бизнеса и дата сайентистов
💪 Примеры процессов, в которых удалось побелить рутину внутри банка
📈 Тренды и новые вызовы области, как за ними угнаться
Мне статья понравилась, советую почитать 🙂
Ребята из Альфы во главе с Женей написали клёвую статью, которая позволит отлично понять как устроена работа в Data Science.
Про что рассказывают в статье:
👨🏫 Причины возникновения рутины с точки зрения пользователя, бизнеса и дата сайентистов
💪 Примеры процессов, в которых удалось побелить рутину внутри банка
📈 Тренды и новые вызовы области, как за ними угнаться
Мне статья понравилась, советую почитать 🙂
Хабр
Побеждаем рутину в Data Science: как перестать быть недопрограммистами и недоисследователями
Data Science ниндзя побеждает рутину и выводит зрелость своей функции на новый уровень. Профессия Data Scientist сейчас стала особенно привлекательна, вовлекая еще больше энтузиастов и даже...
❤16👍7🔥5
✍️ Подробный пост про парсинг
В написании этого поста нам помог Семёнов Богдан, который имеет богатый опыт в парсинге 🙂. Давайте отблагодарим его сердечками под этим постом! ❤️
Вообще, процесс парсинга вебсайта можно разделить на два этапа:
1. Получение html-документа
2. Выбор нужной информации из этого документа
Для получения html-ины используют:
1. Обычный requests, если на сайте вообще нет защиты от парсинга
2. Инструменты для автоматизации веб-браузера, чтобы сайт пропустил вас:
- Selenium - читайте актуальную документацию, потому что, например, ChatGPT-3.5 выдает функции, которых уже нет
- Puppeteer
Для того, чтобы распарсить html-ину, можно использовать:
1. BeautifulSoup
2. Scrapy
📜 5 советов для парсинга:
1. Если на сайте стоит капча, то можно использовать патч Selenium, который не запускает антиботовые сервисы. Вот видос, как с его помощью можно распарсить LinkedIn (внимание, некоторые методы Selenium-а оттуда устарели)
2. Для того, чтобы не быть забаненным по IP, нужно использовать прокси. Вообще, есть разные виды прокси. В идеале использовать ротирующиеся прокси, чтобы они постоянно менялись, и их не банили.
А можно делать так:
– Закупаете несколько (штук 5) прокси (например, тут)
– Пишете код, чтобы менять их с некоторой частотой (норм руководство)
3. Если капча кастомная, то вам, скорее всего придётся вводить её вручную. Для того, чтобы пришёл сигнал, что с парсером что-то пошло не так, можно сделать простенького бота в телеграме, который будет уведомлять вас (если хотите пост про создание тг ботов - давайте наберем 50 огоньков🔥)
4. Seleniumом парсить долго. Ускорить парсинг можно, забирая cookies и headers из Selenium-а, и кидая их в requests. Но это может работать не на всех сайтах(
5. Иногда Selenium залагивает, чтобы бороться с этим, можно ставить ему таймауты –, например, если страница не прогрузилась за 60 секунд, стопать процесс селениума и пересоздавать с этого же урла новый.
Ещё несколько классных советов есть в этой статье, обязательно прочитайте её 🙂
И ставьте сердечки ❤️ под этим постом, если было полезно (если наберем 250, расскажем про парсинг с мобильных приложений)
В написании этого поста нам помог Семёнов Богдан, который имеет богатый опыт в парсинге 🙂. Давайте отблагодарим его сердечками под этим постом! ❤️
Вообще, процесс парсинга вебсайта можно разделить на два этапа:
1. Получение html-документа
2. Выбор нужной информации из этого документа
Для получения html-ины используют:
1. Обычный requests, если на сайте вообще нет защиты от парсинга
2. Инструменты для автоматизации веб-браузера, чтобы сайт пропустил вас:
- Selenium - читайте актуальную документацию, потому что, например, ChatGPT-3.5 выдает функции, которых уже нет
- Puppeteer
Для того, чтобы распарсить html-ину, можно использовать:
1. BeautifulSoup
2. Scrapy
📜 5 советов для парсинга:
1. Если на сайте стоит капча, то можно использовать патч Selenium, который не запускает антиботовые сервисы. Вот видос, как с его помощью можно распарсить LinkedIn (внимание, некоторые методы Selenium-а оттуда устарели)
2. Для того, чтобы не быть забаненным по IP, нужно использовать прокси. Вообще, есть разные виды прокси. В идеале использовать ротирующиеся прокси, чтобы они постоянно менялись, и их не банили.
А можно делать так:
– Закупаете несколько (штук 5) прокси (например, тут)
– Пишете код, чтобы менять их с некоторой частотой (норм руководство)
3. Если капча кастомная, то вам, скорее всего придётся вводить её вручную. Для того, чтобы пришёл сигнал, что с парсером что-то пошло не так, можно сделать простенького бота в телеграме, который будет уведомлять вас (если хотите пост про создание тг ботов - давайте наберем 50 огоньков🔥)
4. Seleniumом парсить долго. Ускорить парсинг можно, забирая cookies и headers из Selenium-а, и кидая их в requests. Но это может работать не на всех сайтах(
5. Иногда Selenium залагивает, чтобы бороться с этим, можно ставить ему таймауты –, например, если страница не прогрузилась за 60 секунд, стопать процесс селениума и пересоздавать с этого же урла новый.
Ещё несколько классных советов есть в этой статье, обязательно прочитайте её 🙂
И ставьте сердечки ❤️ под этим постом, если было полезно (если наберем 250, расскажем про парсинг с мобильных приложений)
Хабр
Как спарсить любой сайт?
Меня зовут Даниил Охлопков , и я расскажу про свой подход к написанию скриптов, извлекающих данные из интернета: с чего начать, куда смотреть и что использовать. Написав тонну парсеров, я придумал...
❤76🔥47👍12
Лучшее что вы можете сделать когда начинаете искать работы на рынке IT как в РФ, так и не РФ - прочитать методичку Бори. И начать применять знания оттуда. Очень рекомендую :)