
Что напечатается в консоли после выполнения кода выше?
Anonymous Poll
68%
true true
22%
true false
7%
false true
3%
false false
Boxing и unboxing
В java 2 типа сущностей — примитивы и ссылочные типы. К первой группе относятся int, long, boolean и остальные типы с маленькой буквы. В таких переменных хранится само значение. Набор действий с примитивами ограничен, зато вычисления происходят с космической скоростью.
К ссылочным типам относится всё остальное: объекты, массивы, интерфейсы и тд. Такие переменные хранят указатель на участок памяти, где находится объект. Объекты занимают больше места, чем примитивы, зато функционал гораздо шире.
Работать с коллекциями приятнее, чем с массивами, поэтому в джава сделаликостыль workaround для примитивных типов — классы-обёртки (Integer, Long, …) и боксинг/анбоксинг.
В целом это удобно, но появляются проблемы:
❌ Неосознанный boxing/unboxing и лишняя трата памяти и времени
❌ NPE в неожиданных местах
❌ Неоднозначная работа с ==
❌ Трудности по работе с массивами
Что происходит в коде выше?
Сигнатура метода asList выглядит так:
Во второй части ситуация менее однозначная. Для массивов и коллекций не работает автоматическое приведение типов и боксинг/анбоксинг:
❌ List<Child> не приводится автоматически к List<Parent>
❌ Массив int не приводится автоматически к массиву Integer
В метод уже приходит ссылка — ссылка на массив примитивов. JVM всё устраивает, и она создаёт List из ссылок на массив.
Получится
⭐️ Заметка 1: немного смуты здесь вносит var. Если писать целиком
⭐️ Заметка 2: сигнатура contains выглядит так:
❓ Как получить нормальный список из массива примитивов?
В java 2 типа сущностей — примитивы и ссылочные типы. К первой группе относятся int, long, boolean и остальные типы с маленькой буквы. В таких переменных хранится само значение. Набор действий с примитивами ограничен, зато вычисления происходят с космической скоростью.
К ссылочным типам относится всё остальное: объекты, массивы, интерфейсы и тд. Такие переменные хранят указатель на участок памяти, где находится объект. Объекты занимают больше места, чем примитивы, зато функционал гораздо шире.
Работать с коллекциями приятнее, чем с массивами, поэтому в джава сделали
В целом это удобно, но появляются проблемы:
❌ Неосознанный boxing/unboxing и лишняя трата памяти и времени
❌ NPE в неожиданных местах
❌ Неоднозначная работа с ==
❌ Трудности по работе с массивами
Что происходит в коде выше?
Сигнатура метода asList выглядит так:
List<T> asList(T… a)Метод ждёт на вход объекты ссылочных типов. В случае stringArr всё ок, передаются 4 ссылки на объект String, и создаётся список с 4 элементами.
Во второй части ситуация менее однозначная. Для массивов и коллекций не работает автоматическое приведение типов и боксинг/анбоксинг:
❌ List<Child> не приводится автоматически к List<Parent>
❌ Массив int не приводится автоматически к массиву Integer
В метод уже приходит ссылка — ссылка на массив примитивов. JVM всё устраивает, и она создаёт List из ссылок на массив.
Получится
List<int[]>, в котором будет один элемент — ссылка на {1,2,3}. Массив с числом не сравнить, поэтому ответ на вопрос перед постом: true false⭐️ Заметка 1: немного смуты здесь вносит var. Если писать целиком
List<Integer> res = Arrays.asList(intArray)то компилятор сразу укажет на несоответствие типов
⭐️ Заметка 2: сигнатура contains выглядит так:
boolean contains(Object o)Метод примет что угодно — строку, примитив (здесь выполнится боксинг) или экземпляр StringBuilder. Поэтому ошибок компиляции нет
❓ Как получить нормальный список из массива примитивов?
var intList = Arrays.stream(intArray).boxed().collect(toList());Закончу на оптимистичной ноте. В рамках Project Valhalla в JVM добавят три новых типа данных: value objects, primitive classes, specialized generics. В двух словах об этом не рассказать, но есть шанс, что через 10 лет код выше будет работать, как ожидается🤭
{kind=link}
Что выведется в консоль в результате работы программы?
Anonymous Poll
1%
0
8%
5
36%
10
4%
Ошибка компиляции в точке А
52%
Ошибка компиляции в точке Б
Что такое effectively final и что с ним делать
Начну с правильного ответа на вопрос выше. В точке Б мы получим предупреждение компилятора: local variables referenced from a lambda expression must be final or effectively final
В этом посте обсудим, что означает effectively final, о чём молчит спецификация и как менять переменные внутри лямбд.
Про модификатор final всё понятно — он запрещает изменение переменной
Чтобы компилятор не ругался, надо выполнить два условия:
1️⃣ Локальная переменная однозначно определена до начала лямбда-выражения
Так не скомпилируется:
JLS 15.27.2 говорит, что ограничение помогает избежать многопоточных проблем: The restriction to effectively final variables prohibits access to dynamically-changing local variables, whose capture would likely introduce concurrency problems
С первого взгляда звучит разумно. Основное применение лямбд — в рамках Stream API. В Stream API есть опция parallel(), которая запускает выполнение в разных потоках. Там и возникнут concurrency problems.
Но я не принимаю это объяснение, потому что:
🤔 С каких пор компилятор волнуют многопоточные проблемы? Вся многопоточка отдана под контроль разработчика с начала времён
🤔 Если локальная переменная станет полем класса, то компилятор перестанет ругаться. При этом вероятность concurrency problems увеличится в разы
Моя гипотеза: требование final/effectively final связано с особенностями реализации лямбд и ограничением модели памяти. Это технические сложности в JVM и ничего больше. Отсутствие многопоточных проблем, о которых говорится в JLS, это всего лишь следствие, а не причина.
❓ Как же менять переменные внутри лямбд?
1️⃣ Сделать переменную полем класса:
2️⃣ Использовать Atomic обёртку
Для примитивов:
Начну с правильного ответа на вопрос выше. В точке Б мы получим предупреждение компилятора: local variables referenced from a lambda expression must be final or effectively final
В этом посте обсудим, что означает effectively final, о чём молчит спецификация и как менять переменные внутри лямбд.
Про модификатор final всё понятно — он запрещает изменение переменной
final int count = 100;
count всегда будет равен 100. Каждый, кто напишет count = 200;будет осуждён компилятором. Для ссылок схема такая же:
final User admin = User.createAdmin();Ссылка
admin всегда будет указывать на объект User с параметрами админа. Никто не может её переприсвоить:❌ admin = new User(…)Effectively final называется переменная, значение которой не меняется после инициализации. По сути это тот же final, но без ключевого слова.
Чтобы компилятор не ругался, надо выполнить два условия:
1️⃣ Локальная переменная однозначно определена до начала лямбда-выражения
Так не скомпилируется:
int x;Вот так норм:
if (…) х = 10
int x;2️⃣ Переменная не меняется внутри лямбды и после неё
if (…) х = 10; else х = 15;
int х = 10;❓ Зачем нужно такое ограничение?
…лямбда…
❌ х = 15
User user = …
…лямбда…
❌ user = userRepository.findByName(…)
✅ user.setTIN(…)
JLS 15.27.2 говорит, что ограничение помогает избежать многопоточных проблем: The restriction to effectively final variables prohibits access to dynamically-changing local variables, whose capture would likely introduce concurrency problems
С первого взгляда звучит разумно. Основное применение лямбд — в рамках Stream API. В Stream API есть опция parallel(), которая запускает выполнение в разных потоках. Там и возникнут concurrency problems.
Но я не принимаю это объяснение, потому что:
🤔 С каких пор компилятор волнуют многопоточные проблемы? Вся многопоточка отдана под контроль разработчика с начала времён
🤔 Если локальная переменная станет полем класса, то компилятор перестанет ругаться. При этом вероятность concurrency problems увеличится в разы
Моя гипотеза: требование final/effectively final связано с особенностями реализации лямбд и ограничением модели памяти. Это технические сложности в JVM и ничего больше. Отсутствие многопоточных проблем, о которых говорится в JLS, это всего лишь следствие, а не причина.
❓ Как же менять переменные внутри лямбд?
1️⃣ Сделать переменную полем класса:
int count;Не лучший вариант, переменная доступна теперь другим потокам. Concurrency problems!
public void m() {
list.forEach(v -> count++);
}
2️⃣ Использовать Atomic обёртку
Для примитивов:
AtomicInteger count = new AtomicInteger(0);Для ссылок:
list.forEach(v -> count.incrementAndGet())
AtomicReference<User> user = new AtomicReference<>();3️⃣ Использовать массив с одним элементом
…map(i -> user.set(…))
int[] res = new int[] {0};
list.forEach(v -> res[0]++);
Популярный вариант, который подходит и для примитивов, и для ссылок. Но мне больше нравится вариант с Atomic:)IDEA: замена кода и сто шагов назад (тихо на пальцах)
Недавно посмотрела доклад с конференции Devoxx и узнала две полезные штуки для дебага. О них и расскажу в посте.
1️⃣ Откат на предыдущий фрейм
У каждого потока есть стек вызовов. Оказывается, по нему можно перемещаться!
Чтобы сделать шаг назад, щёлкните в дебаггере область слева от метода. Внизу поста скриншот — рядом с методом должна появиться стрелка
2️⃣ Замена исполняемого кода
В дебаге нажать Shift-Shift и ввести Reload Changed Classes
или
Run → Debugging Actions → Reload Changed Classes
Нельзя заменять код в том методе, где остановился дебаггер. В любом другом — можно
Фичи отлично работают вместе для простых правок, которые сложно воспроизвести. Например, ошибка воспроизводится редко, на специфичном стенде или при участии других компонентов. План действий такой:
🔸 Зайти в удалённый дебаг, найти ошибку
🔸 Вернуться на пару фреймов назад
🔸 Поправить ошибку, сделать замену класса
🔸 Проверить, что всё ок
При этом сервис продолжит работать с исправленным классом, ну разве не красота🥰
Недавно посмотрела доклад с конференции Devoxx и узнала две полезные штуки для дебага. О них и расскажу в посте.
1️⃣ Откат на предыдущий фрейм
У каждого потока есть стек вызовов. Оказывается, по нему можно перемещаться!
Чтобы сделать шаг назад, щёлкните в дебаггере область слева от метода. Внизу поста скриншот — рядом с методом должна появиться стрелка
2️⃣ Замена исполняемого кода
В дебаге нажать Shift-Shift и ввести Reload Changed Classes
или
Run → Debugging Actions → Reload Changed Classes
Нельзя заменять код в том методе, где остановился дебаггер. В любом другом — можно
Фичи отлично работают вместе для простых правок, которые сложно воспроизвести. Например, ошибка воспроизводится редко, на специфичном стенде или при участии других компонентов. План действий такой:
🔸 Зайти в удалённый дебаг, найти ошибку
🔸 Вернуться на пару фреймов назад
🔸 Поправить ошибку, сделать замену класса
🔸 Проверить, что всё ок
При этом сервис продолжит работать с исправленным классом, ну разве не красота🥰
{kind=link}
Java core адвент календарь 2023
Адвент-календарь — традиционный в Европе календарь для отслеживания времени до Рождества. Обычно это открытка или коробка с 24 окошками, на каждом из которых написано число от 1 до 24. Каждый день открываете одно окошко, и там лежит маленький подарок.
В более широком смысле адвент-календари — это какие-то активности с 1 по 24 декабря.
Давно хотела сделать такую штуку по Java тематике, и наконец сделала🥳
⭐️ Java core advent ⭐️
Что будет:
Каждый день открывается новая тема на тему java core. За основу взяла "золотые хиты" канала, и дополнила их новыми вопросами и практическими моментами. Даже если вы знаете все посты наизусть, всё равно найдёте что-то новое.
Хорошая возможность заполнить пробелы или закрепить знания java core!
Кому будет полезно:
🎄 Junior/Middle java разработчики — быть обязательно
🎄 Сеньоры — если чувствуете пробелы в java core
🎄 Тимлиды — скиньте ссылку младшим коллегам:)
Что по датам:
❄️ 1-24 декабря открываются окошки с темами
❄️ 27 декабря всё закрывается
Вышло, на мой взгляд, очень круто и полезно. Join!
И поделитесь ссылкой с друзьями-джавистами, буду очень рада, если соберётся побольше людей:)
Адвент-календарь — традиционный в Европе календарь для отслеживания времени до Рождества. Обычно это открытка или коробка с 24 окошками, на каждом из которых написано число от 1 до 24. Каждый день открываете одно окошко, и там лежит маленький подарок.
В более широком смысле адвент-календари — это какие-то активности с 1 по 24 декабря.
Давно хотела сделать такую штуку по Java тематике, и наконец сделала🥳
⭐️ Java core advent ⭐️
Что будет:
Каждый день открывается новая тема на тему java core. За основу взяла "золотые хиты" канала, и дополнила их новыми вопросами и практическими моментами. Даже если вы знаете все посты наизусть, всё равно найдёте что-то новое.
Хорошая возможность заполнить пробелы или закрепить знания java core!
Кому будет полезно:
🎄 Junior/Middle java разработчики — быть обязательно
🎄 Сеньоры — если чувствуете пробелы в java core
🎄 Тимлиды — скиньте ссылку младшим коллегам:)
Что по датам:
❄️ 1-24 декабря открываются окошки с темами
❄️ 27 декабря всё закрывается
Вышло, на мой взгляд, очень круто и полезно. Join!
И поделитесь ссылкой с друзьями-джавистами, буду очень рада, если соберётся побольше людей:)
Статистика адвента, первые итоги
На прошлой неделе открылось 7 тем:
❄️ Equals best practices
❄️ Hashcode best practices
❄️ Enums
❄️ Аннотации
❄️ Compact Strings
❄️ String pool
❄️ String deduplication
Участников на текущий момент: 1229!!!
Состав участников:
▫️ Леди — 52%
▫️ Джентельмены — 48%
По грейдам:
🐣 Начинашки — 31%
🐥 Джуниоры — 25%
🦆 Мидлы — 35%
🦅 Сеньоры — 7%
⭐️ Суперзвёзды — 2%
Каждый день стабильно заходят около 250 человек❤️
Планирую провести похожие опросы в середине адвента и ближе к концу. Очень интересно, как все значения будут меняться в динамике!
На прошлой неделе открылось 7 тем:
❄️ Equals best practices
❄️ Hashcode best practices
❄️ Enums
❄️ Аннотации
❄️ Compact Strings
❄️ String pool
❄️ String deduplication
Участников на текущий момент: 1229!!!
Состав участников:
▫️ Леди — 52%
▫️ Джентельмены — 48%
По грейдам:
🐣 Начинашки — 31%
🐥 Джуниоры — 25%
🦆 Мидлы — 35%
🦅 Сеньоры — 7%
⭐️ Суперзвёзды — 2%
Каждый день стабильно заходят около 250 человек❤️
Планирую провести похожие опросы в середине адвента и ближе к концу. Очень интересно, как все значения будут меняться в динамике!
Статистика адвента, выпуск 2
На второй неделе открылись темы:
❄️ Микрооптимизации String
❄️ Сложение строк
❄️ Исключения
❄️ Блок try-catch
❄️ Дженерики
❄️ Дженерики в коллекциях
❄️ Интерфейс Supplier
❄️ Optional
❄️ Stream API
Участников: 1581 ❤️
По расписанию идут около 200 человек. Ещё 300 идут стабильно, но не ежедневно.
На вопрос "какая нагрузка у вас на работе под конец года?" получила такие ответы:
🙃 19% Расслабленная атмосфера
🙂 42% Как обычно, все по плану (я тоже тут)
😬 20% Всё не по плану, но справляемся
😰 17% Работы сильно больше, доделываем всё перед праздниками
Много статистики скопилось по прохождению адвента мальчиками/девочками и разными грейдами. Здесь пока подержу интригу.
Ещё из новостей: закончился 6 поток курса по многопоточке. Осень была для многих непростой (мягко говоря), очень горжусь теми, кто нашёл силы на учёбу💪 Следующий поток запланировала на февраль.
Такие вот краткие сводки. Весь движ сейчас в адвенте, все силы тоже там:)
На второй неделе открылись темы:
❄️ Микрооптимизации String
❄️ Сложение строк
❄️ Исключения
❄️ Блок try-catch
❄️ Дженерики
❄️ Дженерики в коллекциях
❄️ Интерфейс Supplier
❄️ Optional
❄️ Stream API
Участников: 1581 ❤️
По расписанию идут около 200 человек. Ещё 300 идут стабильно, но не ежедневно.
На вопрос "какая нагрузка у вас на работе под конец года?" получила такие ответы:
🙃 19% Расслабленная атмосфера
🙂 42% Как обычно, все по плану (я тоже тут)
😬 20% Всё не по плану, но справляемся
😰 17% Работы сильно больше, доделываем всё перед праздниками
Много статистики скопилось по прохождению адвента мальчиками/девочками и разными грейдами. Здесь пока подержу интригу.
Ещё из новостей: закончился 6 поток курса по многопоточке. Осень была для многих непростой (мягко говоря), очень горжусь теми, кто нашёл силы на учёбу💪 Следующий поток запланировала на февраль.
Такие вот краткие сводки. Весь движ сейчас в адвенте, все силы тоже там:)
Статистика адвента, выпуск 3
На прошлой неделе открылись темы:
❄️ Коллекторы Stream API
❄️ Списки
❄️ Копии коллекций
❄️ Методы Map
❄️ Причуды Map
❄️ Records
❄️ Pattern matching
Участников: 1680 ❤️
Отзывов с 5 звёздочками: 21 (спасибо!!!!!)
Формат адвента мне нравится больше, чем посты. Можно шире развернуть мысль, добавить больше примеров. Участникам тоже веселее — любой интерактив приносит больше пользы, чем просто чтение поста.
Может однажды руки дойдут до полноценного курса по кору. С внутрянкой JVM, лучшими практиками, разбором кейсов, концепций и тд. Знаю, что могу сделать бомбическую штуку. Не знаю, будет ли на это время:)
Напоминаю, что завтра в адвенте откроется последнее окошко, а во вторник всё закроется. Не откладывайте🏃♀️ 🏃
На прошлой неделе открылись темы:
❄️ Коллекторы Stream API
❄️ Списки
❄️ Копии коллекций
❄️ Методы Map
❄️ Причуды Map
❄️ Records
❄️ Pattern matching
Участников: 1680 ❤️
Отзывов с 5 звёздочками: 21 (спасибо!!!!!)
Формат адвента мне нравится больше, чем посты. Можно шире развернуть мысль, добавить больше примеров. Участникам тоже веселее — любой интерактив приносит больше пользы, чем просто чтение поста.
Может однажды руки дойдут до полноценного курса по кору. С внутрянкой JVM, лучшими практиками, разбором кейсов, концепций и тд. Знаю, что могу сделать бомбическую штуку. Не знаю, будет ли на это время:)
Напоминаю, что завтра в адвенте откроется последнее окошко, а во вторник всё закроется. Не откладывайте🏃♀️ 🏃
Итоги
Закончился последний рабочий день в этом году! Наконец-то можно подвести итоги и отдохнуть.
Начну с чуть запоздавших итогов адвента.
Участников: 1787
До конца дошло около 350 человек 🏆
Отзывов с 5 звёздочками: 118 (!!!)
Плюс огромное количество приятных комментариев и сообщений. Сердечко таяло, щёчки краснели, спасибо🥰
Спасибо вообще всем подписчикам! Что читаете посты, ставите реакции и задаёте вопросы. Рада делиться знаниями и получать приятный фидбэк.
Вы лучшие!
Пусть в следующем году у вас всё будет хорошо. Пусть работа приносит удовольствие и много денег, выгорание обойдёт стороной, а жизнь за пределами работы наполняет энергией
С наступающим новым годом!🎄
Закончился последний рабочий день в этом году! Наконец-то можно подвести итоги и отдохнуть.
Начну с чуть запоздавших итогов адвента.
Участников: 1787
До конца дошло около 350 человек 🏆
Отзывов с 5 звёздочками: 118 (!!!)
Плюс огромное количество приятных комментариев и сообщений. Сердечко таяло, щёчки краснели, спасибо🥰
Спасибо вообще всем подписчикам! Что читаете посты, ставите реакции и задаёте вопросы. Рада делиться знаниями и получать приятный фидбэк.
Вы лучшие!
Пусть в следующем году у вас всё будет хорошо. Пусть работа приносит удовольствие и много денег, выгорание обойдёт стороной, а жизнь за пределами работы наполняет энергией
С наступающим новым годом!🎄
Для работы с сущностями User используется Hibernate. Как бы вы определили метод hashcode для этого класса?
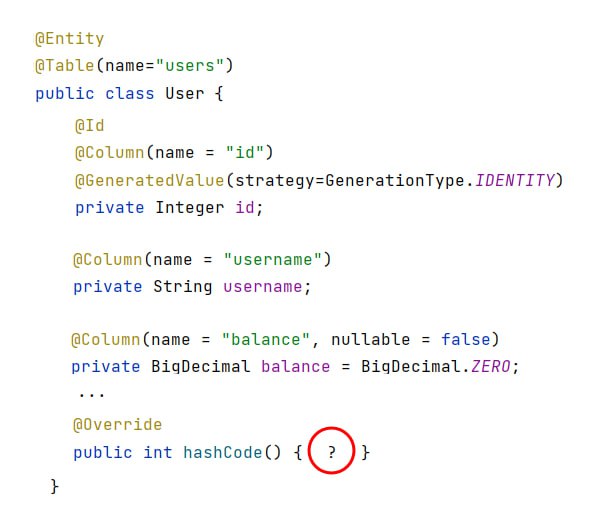{kind=link}
Как бы вы определили метод hashcode для этого класса?
Anonymous Poll
34%
return id;
2%
return username;
0%
return balance;
24%
return Objects.hash(id, username);
6%
return Objects.hash(username, balance);
18%
return Objects.hash(id, username, balance);
3%
return 13;
14%
Можно вообще не определять hashcode
Hashcode для Hibernate сущностей
Год новый, а темы всё те же. В декабрьском адвенте разгорелась горячая дискуссия на тему hashcode. Встал такой вопрос:
Как определить hashcode для сущностей Hibernate? Что делать, если объект пока не сохранён в БД и у него нет id?
В этом вопросе часто упоминается статья Thorben Janssen Ultimate Guide to Implementing equals() and hashCode() with Hibernate
В самом конце там вывод: если для сущности id генерируется в БД, то hashcode должен возвращать константу.
Почему это не лучший вариант?
Контракт соблюдается, всё работает корректно. Но задача хэша — быстрая проверка схожести объектов. Мы теряем преимущество быстрого поиска, и хэшсет будет работать как список. Так будет и для новых объектов, и для уже сохранённых (у которых id есть).
Другие авторы рекомендуют считать хэш Hibernate сущностей на основе всех полей кроме id. В чём недостатки такого решения:
❌ Если поля изменяемые, есть шанс потерять объект внутри HashSet
❌ Цель хэша — быстрая проверка. Если считать хэш всех полей, с тем же успехом можно использовать списки и сравнение через equals
Что же делать?
1️⃣ Использовать для хэша любое неизменяемое поле
Даже если поле не уникальное, распределение хэшей будет лучше, чем у константы
2️⃣ Не использовать хэш-структуры для новых объектов
Новые объекты собирать в список:
🔸 Hashcode нужен только, когда структура используется в hash-based структурах. Если новые объекты не складываются в HashSet или HashMap, то проблемы вообще нет
🔸 Если вы хотите возвращать в хэшкод константу, рассмотрите вариант хранения сущностей в ArrayList или TreeSet
Ответ на вопрос перед постом: зависит от сценариев использования. Если новые объекты User собираются в коллекцию, я бы складывала в список, а hashcode реализовала как
И более глобальные выводы:
Хороших материалов по разработке мало. Но даже в хороших легко свернуть не туда. Статья Thorben Janssen в целом ок, но итог немного сбивает с толку. Сравните:
💁🏼♂️ "Если для сущности id генерируется в БД, hashcode должен возвращать константу"
💁🏼 "Если новые Hibernate сущности складываются в hash структуры, и у них нет final полей, то для соблюдения контракта можно использовать в hashcode константу"
Второй вариант корректнее, но первый проще и лучше запоминается.
Не попадайте в эту ловушку. Задача разработчика — разобраться в сценариях, оценить варианты и найти подходящий😌
Год новый, а темы всё те же. В декабрьском адвенте разгорелась горячая дискуссия на тему hashcode. Встал такой вопрос:
Как определить hashcode для сущностей Hibernate? Что делать, если объект пока не сохранён в БД и у него нет id?
В этом вопросе часто упоминается статья Thorben Janssen Ultimate Guide to Implementing equals() and hashCode() with Hibernate
В самом конце там вывод: если для сущности id генерируется в БД, то hashcode должен возвращать константу.
Почему это не лучший вариант?
Контракт соблюдается, всё работает корректно. Но задача хэша — быстрая проверка схожести объектов. Мы теряем преимущество быстрого поиска, и хэшсет будет работать как список. Так будет и для новых объектов, и для уже сохранённых (у которых id есть).
Другие авторы рекомендуют считать хэш Hibernate сущностей на основе всех полей кроме id. В чём недостатки такого решения:
❌ Если поля изменяемые, есть шанс потерять объект внутри HashSet
❌ Цель хэша — быстрая проверка. Если считать хэш всех полей, с тем же успехом можно использовать списки и сравнение через equals
Что же делать?
1️⃣ Использовать для хэша любое неизменяемое поле
Даже если поле не уникальное, распределение хэшей будет лучше, чем у константы
2️⃣ Не использовать хэш-структуры для новых объектов
Новые объекты собирать в список:
List users = …Тогда в хэшкоде можно спокойно использовать id и для уже сохранённых объектов хэшсет будет работать как надо:
users.forEach(u -> session.save(u));
Set users = …Итого:
if (!users.contains(…)) {…}
🔸 Hashcode нужен только, когда структура используется в hash-based структурах. Если новые объекты не складываются в HashSet или HashMap, то проблемы вообще нет
🔸 Если вы хотите возвращать в хэшкод константу, рассмотрите вариант хранения сущностей в ArrayList или TreeSet
Ответ на вопрос перед постом: зависит от сценариев использования. Если новые объекты User собираются в коллекцию, я бы складывала в список, а hashcode реализовала как
return id; Но ситуации бывают разные, решение не универсально.И более глобальные выводы:
Хороших материалов по разработке мало. Но даже в хороших легко свернуть не туда. Статья Thorben Janssen в целом ок, но итог немного сбивает с толку. Сравните:
💁🏼♂️ "Если для сущности id генерируется в БД, hashcode должен возвращать константу"
💁🏼 "Если новые Hibernate сущности складываются в hash структуры, и у них нет final полей, то для соблюдения контракта можно использовать в hashcode константу"
Второй вариант корректнее, но первый проще и лучше запоминается.
Не попадайте в эту ловушку. Задача разработчика — разобраться в сценариях, оценить варианты и найти подходящий😌
Типы кэшей
Если спросить разработчика, что такое кэш, он скорее всего ответит:
— Кэш — хранилище типа ключ-значение. Позволяет снизить количество запросов к БД, другому сервису или не выполнять повторно сложные вычисления
Это, безусловно, правда, но не вся. В этом посте кратко опишу, что ещё умеют делать кэши и какие они бывают.
1️⃣ Кэш внутри сервиса
Хранится только в оперативной памяти. При выключении сервиса кэш пропадает. При включении — заполняется. Популярны два варианта:
🔸 ConcurrentHashMap: полностью ручное управление. Разработчик пишет код по наполнению кэша, обновлению и удалению значений
🔸 Google Guava Cache: более продвинутый вариант. Очищает кэш, уведомляет об удалении, предоставляет статистику
2️⃣ Удалённый кэш
Не связан с конкретным сервисом и запущен в отдельном процессе
✅ Доступен для нескольких сервисов
✅ Хранит данные на нескольких уровнях — в оперативной памяти и на диске
3️⃣ Распределённый кэш
Данные хранятся в нескольких процессах. Один экземпляр обычно называют нодой
✅ Шардирование. Распределяем данные по разным нодам и в итоге храним больше данных
✅ Репликация. Дублируем данные на разные ноды и повышаем доступность
Уровни 2-3 это скорее ступени эволюции кэшей. Большинство реализаций находятся на уровне 4:
4️⃣ In-memory data grid (IMDG)
Распределённый кэш с дополнительными фичами. Например:
▫️ Атомарный апдейт (вместо чтения и перезаписи)
▫️ Подписка на изменения в кэше
▫️ Поддержка транзакций
▫️ SQL-like запросы
▫️ Средства синхронизации (распределённый lock, очередь)
▫️ Продвинутый мониторинг
▫️ Выполнение скриптов
У многих кэшей есть платная и бесплатная версии. Многие фичи из списка выше доступны только платно.
В вакансиях чаще всего встречается Redis, чуть отстаёт Hazelcast. Также видела в проектах Memcached, Ehcache, Aerospike, Ignite/GridGain, Coherence. В их описании нет слова "кэш", как минимум distributed real-time in-memory streaming data platform🙂
Рекомендую погулять по документации того же Redis или Hazelcast, может для вашего проекта найдётся что-то полезное.
Если спросить разработчика, что такое кэш, он скорее всего ответит:
— Кэш — хранилище типа ключ-значение. Позволяет снизить количество запросов к БД, другому сервису или не выполнять повторно сложные вычисления
Это, безусловно, правда, но не вся. В этом посте кратко опишу, что ещё умеют делать кэши и какие они бывают.
1️⃣ Кэш внутри сервиса
Хранится только в оперативной памяти. При выключении сервиса кэш пропадает. При включении — заполняется. Популярны два варианта:
🔸 ConcurrentHashMap: полностью ручное управление. Разработчик пишет код по наполнению кэша, обновлению и удалению значений
🔸 Google Guava Cache: более продвинутый вариант. Очищает кэш, уведомляет об удалении, предоставляет статистику
2️⃣ Удалённый кэш
Не связан с конкретным сервисом и запущен в отдельном процессе
✅ Доступен для нескольких сервисов
✅ Хранит данные на нескольких уровнях — в оперативной памяти и на диске
3️⃣ Распределённый кэш
Данные хранятся в нескольких процессах. Один экземпляр обычно называют нодой
✅ Шардирование. Распределяем данные по разным нодам и в итоге храним больше данных
✅ Репликация. Дублируем данные на разные ноды и повышаем доступность
Уровни 2-3 это скорее ступени эволюции кэшей. Большинство реализаций находятся на уровне 4:
4️⃣ In-memory data grid (IMDG)
Распределённый кэш с дополнительными фичами. Например:
▫️ Атомарный апдейт (вместо чтения и перезаписи)
▫️ Подписка на изменения в кэше
▫️ Поддержка транзакций
▫️ SQL-like запросы
▫️ Средства синхронизации (распределённый lock, очередь)
▫️ Продвинутый мониторинг
▫️ Выполнение скриптов
У многих кэшей есть платная и бесплатная версии. Многие фичи из списка выше доступны только платно.
В вакансиях чаще всего встречается Redis, чуть отстаёт Hazelcast. Также видела в проектах Memcached, Ehcache, Aerospike, Ignite/GridGain, Coherence. В их описании нет слова "кэш", как минимум distributed real-time in-memory streaming data platform🙂
Рекомендую погулять по документации того же Redis или Hazelcast, может для вашего проекта найдётся что-то полезное.
Оптимизация запросов
В этом после хочу рассказать основы оптимизации запросов в БД. Буду говорить на примере Postgre, но в других БД процесс похож.
Шаг 0. Вспоминаем основы
При выполнении запроса участвуют два процесса:
▪️ Планировщик — составляет план выполнения запроса. Какие таблицы обойти, что проверить и в какой последовательности
▪️ Исполнитель — извлекает данные по заданному плану
Разработчик может создать дополнительные структуры данных — индексы. Индексы помогают быстрее выполнять запросы, но занимают много места. Если данные в таблице занимают 1 ГБ, то индекс с id займёт 250 МБ.
Шаг 1. Ищем, что оптимизировать
Смотрим таблицу
Ищем запросы, которые выполняются часто или долго.
Шаг 2. Работаем с конкретным запросом
Для экспериментов берём тестовую базу с большим количеством данных. Минимум миллион записей, иначе эффект оптимизаций не будет заметен.
Прогоняем запрос через EXPLAIN ANALYZE:
▪️ planning time — время планирования запроса
▪️ execution time — время выполнения запроса. Работаем с этим значением
Можно поиграть с условиями, порядком соединения таблиц и разными функциями. Обратите внимание на способ обхода таблицы:
🔸 поиск по условию (where name = …)
🔸 проверка уникальности поля
🔸 проверка внешнего ключа (foreign key)
Решение здесь простое — добавить индекс по проблемному полю. Базовый вариант выглядит так:
▫️ Запустить
▫️ Порадоваться снижению execution time
Для оптимизаций популярных и тяжёлых запросов добавление индекса оправдано. Разумеется, не нужно добавлять индексы для всех запросов и всех условий. Индексы занимают много места и замедляют запись в базу.
В оптимизации запросов огромное количество нюансов, но большинство проблем решается кэшем и добавлением индекса. Более сложные случаи лучше обсуждать с коллегами DBA😌
В этом после хочу рассказать основы оптимизации запросов в БД. Буду говорить на примере Postgre, но в других БД процесс похож.
Шаг 0. Вспоминаем основы
При выполнении запроса участвуют два процесса:
▪️ Планировщик — составляет план выполнения запроса. Какие таблицы обойти, что проверить и в какой последовательности
▪️ Исполнитель — извлекает данные по заданному плану
Разработчик может создать дополнительные структуры данных — индексы. Индексы помогают быстрее выполнять запросы, но занимают много места. Если данные в таблице занимают 1 ГБ, то индекс с id займёт 250 МБ.
Шаг 1. Ищем, что оптимизировать
Смотрим таблицу
pg_stat_statements — там собирается статистика по запросам. Чтобы получить достоверные данные, берём статистику с продакшн базы.Ищем запросы, которые выполняются часто или долго.
Шаг 2. Работаем с конкретным запросом
Для экспериментов берём тестовую базу с большим количеством данных. Минимум миллион записей, иначе эффект оптимизаций не будет заметен.
Прогоняем запрос через EXPLAIN ANALYZE:
EXPLAIN ANALYZE SELECT * FROM users where name = ’K’;EXPLAIN пишет только план выполнения запроса. EXPLAIN ANALYZE выполняет запрос и показывает
▪️ planning time — время планирования запроса
▪️ execution time — время выполнения запроса. Работаем с этим значением
Можно поиграть с условиями, порядком соединения таблиц и разными функциями. Обратите внимание на способ обхода таблицы:
Index Scan using name_index on — при выполнении запроса используется индекс, и это отличноSeq Scan on означает, что происходит долгий последовательный обход таблицы. Причиной может быть🔸 поиск по условию (where name = …)
🔸 проверка уникальности поля
🔸 проверка внешнего ключа (foreign key)
Решение здесь простое — добавить индекс по проблемному полю. Базовый вариант выглядит так:
CREATE INDEX index_name ON users(name);Дальше всё просто:
▫️ Запустить
EXPLAIN ANALYZE
▫️ Увидеть в плане выполнения новый индекс▫️ Порадоваться снижению execution time
Для оптимизаций популярных и тяжёлых запросов добавление индекса оправдано. Разумеется, не нужно добавлять индексы для всех запросов и всех условий. Индексы занимают много места и замедляют запись в базу.
В оптимизации запросов огромное количество нюансов, но большинство проблем решается кэшем и добавлением индекса. Более сложные случаи лучше обсуждать с коллегами DBA😌
Форматы обучения
Сегодня чуть подробнее расскажу про формат и внутрянку курса!
Помните декабрьский адвент? Он занимал мало времени и отлично справился со своей задачей: повторить материал или закрыть небольшие пробелы. Поэтому я так часто повторяла, что это не курс.
В случае с курсом подход другой.
Его задача — научить человека правильно пользоваться java.util.concurrent. Поэтому каждая тема разбирается до мелочей и обязательно закрепляется на практике.
Как выглядит каждый урок:
▫️ Небольшая лекция (до 20 минут)
▫️ Тесты на закрепление и вопросы с собеседований
▫️ Практика: решение типовых энтерпрайзных задач и код-ревью уже написанного кода
В среднем прохождение занимает 4 часа в неделю. Вся учёба идёт асинхронно, вы сами решаете, как распределить нагрузку по неделе.
👨🦱 “Курс очень плотный и нельзя расслабляться, совмещать с работой и прочим бытом непросто, но все реально. Главное не копить это на конец недели, а делать понемногу каждый день”
👨🦱 ”Приготовьтесь, вы будете очень много слушать, читать и перечитывать, ковыряться в доках, в исходниках библиотек, перевернете весь интернет в поисках ответов на уточняющие вопросы”
👨🦱 ”Насыщенные домашние задания. Не "повтори услышанное за преподавателем" и не "а не вольтметром ли измеряется напряжение", часто приходилось действительно попотеть. Вопросы отчасти перекрываются с материалом лекций, а отчасти расширяют его, что особенно круто - когда что-то откопал своими усилиями, запоминается оно гораздо лучше”
Варианты обучения:
1️⃣ С обратной связью (моей)
Самый эффективный способ. Проверяю все практические задания, вижу именно ваши пробелы и помогаю их устранить.
👨🦱 “Я бы брал курс с обратной связью, так как преподаватель задает вопросы на понимание используемых инструментов и процессов, что мотивирует лучше разобраться в теме”
👨🦱 ”Обратная связь - самая сильная и самая замечательная часть этого курса, что означает, что, даже если в теме что-то не устраивает, всегда можно спросить по интересующим именно вас моментам”
👨🦱 ”Задачи больше на понимание, с подводными камнями, комментарии преподавателя бесценны 😍 Не нужно писать тонны кода, но нужно разобраться, что происходит, и залезть в документацию”
Размер группы ограничен, сейчас осталось 12 мест
2️⃣ Без обратной связи
Основной педагогический челлендж любого курса — организовать адекватную самостоятельную работу.
Практические задания на этом тарифе тоже есть, но требуют больше вовлечения от ученика. Для заданий с кодом есть юнит-тесты и примеры реализаций. Для код-ревью — набор вопросов, которые помогут прийти к верному решению. Например, даётся код и к нему вопросы:
❓ Какие гарантии даёт метод А?
❓ У какого объекта захвачен монитор в методе Б?
❓ А в методе Ц?
И только потом ❓ Какие проблемы возможны в этом коде?
Путь к ответу длиннее, но более последовательный. По статистике ответов такой подход работает лучше! Путь к успеху — не забивать на непонятные моменты и стараться найти ответ в предложенных материалах.
Если вы дисциплинированы, готовы разобраться в многопоточке и потратить меньше денег, то возьмите тариф без обратной связи, он тоже классный!
Запись на оба тарифа здесь → http://fillthegaps.ru/mt
Сегодня чуть подробнее расскажу про формат и внутрянку курса!
Помните декабрьский адвент? Он занимал мало времени и отлично справился со своей задачей: повторить материал или закрыть небольшие пробелы. Поэтому я так часто повторяла, что это не курс.
В случае с курсом подход другой.
Его задача — научить человека правильно пользоваться java.util.concurrent. Поэтому каждая тема разбирается до мелочей и обязательно закрепляется на практике.
Как выглядит каждый урок:
▫️ Небольшая лекция (до 20 минут)
▫️ Тесты на закрепление и вопросы с собеседований
▫️ Практика: решение типовых энтерпрайзных задач и код-ревью уже написанного кода
В среднем прохождение занимает 4 часа в неделю. Вся учёба идёт асинхронно, вы сами решаете, как распределить нагрузку по неделе.
👨🦱 “Курс очень плотный и нельзя расслабляться, совмещать с работой и прочим бытом непросто, но все реально. Главное не копить это на конец недели, а делать понемногу каждый день”
👨🦱 ”Приготовьтесь, вы будете очень много слушать, читать и перечитывать, ковыряться в доках, в исходниках библиотек, перевернете весь интернет в поисках ответов на уточняющие вопросы”
👨🦱 ”Насыщенные домашние задания. Не "повтори услышанное за преподавателем" и не "а не вольтметром ли измеряется напряжение", часто приходилось действительно попотеть. Вопросы отчасти перекрываются с материалом лекций, а отчасти расширяют его, что особенно круто - когда что-то откопал своими усилиями, запоминается оно гораздо лучше”
Варианты обучения:
1️⃣ С обратной связью (моей)
Самый эффективный способ. Проверяю все практические задания, вижу именно ваши пробелы и помогаю их устранить.
👨🦱 “Я бы брал курс с обратной связью, так как преподаватель задает вопросы на понимание используемых инструментов и процессов, что мотивирует лучше разобраться в теме”
👨🦱 ”Обратная связь - самая сильная и самая замечательная часть этого курса, что означает, что, даже если в теме что-то не устраивает, всегда можно спросить по интересующим именно вас моментам”
👨🦱 ”Задачи больше на понимание, с подводными камнями, комментарии преподавателя бесценны 😍 Не нужно писать тонны кода, но нужно разобраться, что происходит, и залезть в документацию”
Размер группы ограничен, сейчас осталось 12 мест
2️⃣ Без обратной связи
Основной педагогический челлендж любого курса — организовать адекватную самостоятельную работу.
Практические задания на этом тарифе тоже есть, но требуют больше вовлечения от ученика. Для заданий с кодом есть юнит-тесты и примеры реализаций. Для код-ревью — набор вопросов, которые помогут прийти к верному решению. Например, даётся код и к нему вопросы:
❓ Какие гарантии даёт метод А?
❓ У какого объекта захвачен монитор в методе Б?
❓ А в методе Ц?
И только потом ❓ Какие проблемы возможны в этом коде?
Путь к ответу длиннее, но более последовательный. По статистике ответов такой подход работает лучше! Путь к успеху — не забивать на непонятные моменты и стараться найти ответ в предложенных материалах.
Если вы дисциплинированы, готовы разобраться в многопоточке и потратить меньше денег, то возьмите тариф без обратной связи, он тоже классный!
Запись на оба тарифа здесь → http://fillthegaps.ru/mt
Задачки на ООП
На собеседованиях на middle позицию последнее время часто дают задачки на объектно-ориентированный дизайн. Определяется ситуация и требования, для них кандидат рисует диаграмму классов и определяет API. Код не пишется, но можно обсудить конкретные шаги для некоторых сценариев.
Очень классный тип заданий! Занимают 15-30 минут, выполняются прямо на собесе, отлично проверяют прикладные навыки кандидата👌
Поделюсь тремя примерами для тренировки.
1️⃣ Библиотека
У каждой книги есть несколько копий. Пользователь может взять до 5 книг на месяц. Затем он может продлить использование ещё на месяц.
Если книги не возвращены в срок, система генерирует алерт.
Если нужной книги в библиотеке нет, пользователь может её зарезервировать. Как только она появится, библиотекарь увидит сообщение “пользователь Х зарезервировал книгу Y”. Библиотекарь звонит пользователю X, и в течение 5 дней книга ждёт своего читателя.
Напомню задание: определить API и нарисовать диаграмму классов.
Усложнение: у библиотеки есть несколько филиалов. Пользователь может заказать книгу и сдать её в любой филиал.
2️⃣ Парковка
На парковке доступно определённое количество мест. Они могут быть 3х размеров — S, M и L.
На парковку заезжают транспортные средства разных типов — мотоциклы, легковые автомобили и грузовые. Они занимают места следующим образом:
▫️ S — помещается один мотоцикл
▫️ M — два мотоцикла или одна легковушка
▫️ L — 4 мотоцикла, 2 легковушки или один грузовичок
Паркинг должен показывать количество свободных мест всех типов.
При въезде транспортного средства ему нужно указать, на какое место встать. Чем плотнее заставлена парковка — тем лучше.
Для каждого транспортного средства своя ставка. Также прайс зависит от времени стоянки. Например, для легкового автомобиля:
💲 первые 10 минут — бесплатно
💲 следующие 50 минут — 300 рублей
💲 1-3 час — 250 рублей в час
💲 3 час и далее — 200 рублей в час
Оплата считается, когда транспортное средство покидает парковку.
3️⃣ Автомат с едой
В автомате есть несколько слотов. В каждом слоте лежит товар с указанной ценой.
В начале работы в автомате есть какое-то количество денег каких-то номиналов. Автомат принимает оплату картой и наличные, может выдавать сдачу. Если отдать сдачу невозможно, продажа отменяется, а деньги возвращаются покупателю.
В автомате есть рулон с чеками. После каждой успешной транзакции покупателю выдаётся чек. Нет чеков — продажа не совершается.
В системе три роли:
👨 Оператор. Ставит новый рулон с чеками, балансирует наличные деньги
🙎♂️ Покупатель. Выбирает товар, способ оплаты и вносит деньги. При оплате наличными получает сдачу. Если сдачи нет, забирает свои деньги назад. Если всё ок, покупатель забирает чек и товар
🤵 Менеджер. Видит статистику по операциям и балансирует наличку
Таких задач море: бронь мест в отеле или билетов в кинотеатре, дизайн StackOverflow или Twitter как монолитного приложения, имитация шахмат или покера. Плюс огромное количество вариаций и усложнений.
Если вы только подбираетесь к Junior позиции, можете взять эти примеры как основу для пет-проекта. Добавьте Spring, БД, потокобезопасность, юнит-тесты — и проект для портфолио готов👌
На собеседованиях на middle позицию последнее время часто дают задачки на объектно-ориентированный дизайн. Определяется ситуация и требования, для них кандидат рисует диаграмму классов и определяет API. Код не пишется, но можно обсудить конкретные шаги для некоторых сценариев.
Очень классный тип заданий! Занимают 15-30 минут, выполняются прямо на собесе, отлично проверяют прикладные навыки кандидата👌
Поделюсь тремя примерами для тренировки.
1️⃣ Библиотека
У каждой книги есть несколько копий. Пользователь может взять до 5 книг на месяц. Затем он может продлить использование ещё на месяц.
Если книги не возвращены в срок, система генерирует алерт.
Если нужной книги в библиотеке нет, пользователь может её зарезервировать. Как только она появится, библиотекарь увидит сообщение “пользователь Х зарезервировал книгу Y”. Библиотекарь звонит пользователю X, и в течение 5 дней книга ждёт своего читателя.
Напомню задание: определить API и нарисовать диаграмму классов.
Усложнение: у библиотеки есть несколько филиалов. Пользователь может заказать книгу и сдать её в любой филиал.
2️⃣ Парковка
На парковке доступно определённое количество мест. Они могут быть 3х размеров — S, M и L.
На парковку заезжают транспортные средства разных типов — мотоциклы, легковые автомобили и грузовые. Они занимают места следующим образом:
▫️ S — помещается один мотоцикл
▫️ M — два мотоцикла или одна легковушка
▫️ L — 4 мотоцикла, 2 легковушки или один грузовичок
Паркинг должен показывать количество свободных мест всех типов.
При въезде транспортного средства ему нужно указать, на какое место встать. Чем плотнее заставлена парковка — тем лучше.
Для каждого транспортного средства своя ставка. Также прайс зависит от времени стоянки. Например, для легкового автомобиля:
💲 первые 10 минут — бесплатно
💲 следующие 50 минут — 300 рублей
💲 1-3 час — 250 рублей в час
💲 3 час и далее — 200 рублей в час
Оплата считается, когда транспортное средство покидает парковку.
3️⃣ Автомат с едой
В автомате есть несколько слотов. В каждом слоте лежит товар с указанной ценой.
В начале работы в автомате есть какое-то количество денег каких-то номиналов. Автомат принимает оплату картой и наличные, может выдавать сдачу. Если отдать сдачу невозможно, продажа отменяется, а деньги возвращаются покупателю.
В автомате есть рулон с чеками. После каждой успешной транзакции покупателю выдаётся чек. Нет чеков — продажа не совершается.
В системе три роли:
👨 Оператор. Ставит новый рулон с чеками, балансирует наличные деньги
🙎♂️ Покупатель. Выбирает товар, способ оплаты и вносит деньги. При оплате наличными получает сдачу. Если сдачи нет, забирает свои деньги назад. Если всё ок, покупатель забирает чек и товар
🤵 Менеджер. Видит статистику по операциям и балансирует наличку
Таких задач море: бронь мест в отеле или билетов в кинотеатре, дизайн StackOverflow или Twitter как монолитного приложения, имитация шахмат или покера. Плюс огромное количество вариаций и усложнений.
Если вы только подбираетесь к Junior позиции, можете взять эти примеры как основу для пет-проекта. Добавьте Spring, БД, потокобезопасность, юнит-тесты — и проект для портфолио готов👌
Читали Designing Data Intensive Applications (книжку с кабаном)?
Anonymous Poll
6%
Да, полностью прочитал
14%
Начинал, но не закончил
4%
Читал выборочные главы
44%
Нет, но планирую
31%
Нет, и пока не хочу
Книги для разработчиков
Читать или не читать книги — вопрос индивидуальный. Огромное количество информации есть в виде статей, видяшек и туториалов. Для проработки точечных вопросов это отличный вариант.
Книги — штука фундаментальная. Для выбранной темы вы получите последовательное изложение и множество деталей. В этом их огромный плюс. Заметила по себе и многим знакомым: чем старше по грейду становишься, тем больше тянет на книжки:)
В посте поделюсь полезными приёмами по работе с книгами на примере Designing Data Intensive Applications. Она же "книжка с кабаном" или DDIA.
Предварительный ресёрч
Помогает понять, стоит ли тратить время на книгу, насколько интересны темы и подходят ли они вам по уровню. Лучше потратить один час на исследование, чем десятки часов на бесполезную или неактуальную книгу. Что можно сделать:
🔸 Пройтись по заключению к каждой главе
Обычно это 1-2 страницы с концентратом информации и главными выводами
🔸 Посмотреть краткое содержание
У популярных книг на youtube есть плейлисты с кратким содержанием. Чтобы найти — просто напишете в поиске название книги. Например, вот плейлист для DDIA. Каждая глава пересказывается за 10-15 минут.
🔸 Прочитать конспект
Многие пишут конспекты по книгам и делятся ими с окружающим миром. Найти очень просто:
Как прочитать книгу, в которой больше 10 страниц
Большой объём часто вгоняет в тоску. Что может здесь помочь:
🔹 Читать в группе
Объединиться с коллегами или друзьями и установить распорядок. Например, выбираете главу, которую надо прочитать за неделю, в пятницу созваниваетесь и обсуждаете прочитанное.
🔹 Присоединиться к читальному клубу
Я знаю только один, сейчас они читают Art of Multiprocessor Programming и Effective Java. Подписчик подсказал ещё вот этот. В крупных компаниях организуют похожие клубы, это надо узнать у HR.
🔹 Маленькие шаги
Поставьте себе выполнимый план и придерживайтесь его. Допустим, каждый день читать по 10 страниц или по 20 минут. Важно удобно встроить чтение в вашу жизнь. Например, если после работы нет сил, то попробуйте читать до работы.
🔹 Не читать целиком
Прочитать только интересную главу или пропускать главы, которые кажутся очевидными. Но если чувствуете высокий уровень книги, лучше прочитать полностью.
🔹 Не читать🙂
Если автор нудный или чтение идёт тяжело, можно взять темы из содержания и последовательно искать их на Youtube или в гугле. Не для всех книг подойдёт, но для некоторых норм.
Что советуешь прочитать?
Универсальных рекомендаций нет, всё зависит от текущих задач и ваших интересов. Джуниорам полезно прочитать Effective Java. Хочется погрузиться в недра БД — Database Internals. Активно следите за продом — Site Reliability Engeneering от гугла. Прочитали DDIA и хотите продолжения — Designing Distributed System. Разобраться в операционных системах или сетях — Таненбаум.
Это я сама себе советую, а надо ли вам это читать — не знаю:) Спросите у старших коллег, они наверняка подскажут что-то релевантное вашему опыту и задачам проекта.
Читать или не читать книги — вопрос индивидуальный. Огромное количество информации есть в виде статей, видяшек и туториалов. Для проработки точечных вопросов это отличный вариант.
Книги — штука фундаментальная. Для выбранной темы вы получите последовательное изложение и множество деталей. В этом их огромный плюс. Заметила по себе и многим знакомым: чем старше по грейду становишься, тем больше тянет на книжки:)
В посте поделюсь полезными приёмами по работе с книгами на примере Designing Data Intensive Applications. Она же "книжка с кабаном" или DDIA.
Предварительный ресёрч
Помогает понять, стоит ли тратить время на книгу, насколько интересны темы и подходят ли они вам по уровню. Лучше потратить один час на исследование, чем десятки часов на бесполезную или неактуальную книгу. Что можно сделать:
🔸 Пройтись по заключению к каждой главе
Обычно это 1-2 страницы с концентратом информации и главными выводами
🔸 Посмотреть краткое содержание
У популярных книг на youtube есть плейлисты с кратким содержанием. Чтобы найти — просто напишете в поиске название книги. Например, вот плейлист для DDIA. Каждая глава пересказывается за 10-15 минут.
🔸 Прочитать конспект
Многие пишут конспекты по книгам и делятся ими с окружающим миром. Найти очень просто:
[название книги] summaryХорошие конспекты по DDIA: покороче и подлиннее.
Как прочитать книгу, в которой больше 10 страниц
Большой объём часто вгоняет в тоску. Что может здесь помочь:
🔹 Читать в группе
Объединиться с коллегами или друзьями и установить распорядок. Например, выбираете главу, которую надо прочитать за неделю, в пятницу созваниваетесь и обсуждаете прочитанное.
🔹 Присоединиться к читальному клубу
Я знаю только один, сейчас они читают Art of Multiprocessor Programming и Effective Java. Подписчик подсказал ещё вот этот. В крупных компаниях организуют похожие клубы, это надо узнать у HR.
🔹 Маленькие шаги
Поставьте себе выполнимый план и придерживайтесь его. Допустим, каждый день читать по 10 страниц или по 20 минут. Важно удобно встроить чтение в вашу жизнь. Например, если после работы нет сил, то попробуйте читать до работы.
🔹 Не читать целиком
Прочитать только интересную главу или пропускать главы, которые кажутся очевидными. Но если чувствуете высокий уровень книги, лучше прочитать полностью.
🔹 Не читать🙂
Если автор нудный или чтение идёт тяжело, можно взять темы из содержания и последовательно искать их на Youtube или в гугле. Не для всех книг подойдёт, но для некоторых норм.
Что советуешь прочитать?
Универсальных рекомендаций нет, всё зависит от текущих задач и ваших интересов. Джуниорам полезно прочитать Effective Java. Хочется погрузиться в недра БД — Database Internals. Активно следите за продом — Site Reliability Engeneering от гугла. Прочитали DDIA и хотите продолжения — Designing Distributed System. Разобраться в операционных системах или сетях — Таненбаум.
Это я сама себе советую, а надо ли вам это читать — не знаю:) Спросите у старших коллег, они наверняка подскажут что-то релевантное вашему опыту и задачам проекта.